Last updated on February 4, 2026 11:14 PM
本系列为斯坦福 Stanford CS336 | Language Modeling from Scratch 课程的作业笔记。
该作业实现难度较大,实验文档正文就有足足 46 页,对算力也有相当大的需求。在此衷心感谢北京大学 Linux 俱乐部提供的算力资源和组织讨论平台。
本 lab 的相关代码仓库在此处 ,将其 clone 到本地即可。该实验使用 uv 管理环境,代码需要在 cs336_basics/ 中完成,test/ 中为测试点,在完成各个功能的时候需要同步实现 adapters.py 里面的接口。
这个 lab 需要实现:
BPE 分词器;
从零开始实现 一个 Transformer 模型(仅从 torch 里面的基本组件开始);
具体规则:
We expect you to build these components from scratch. In particular, you may not use any definitions from torch.nn, torch.nn.functional, or torch.optim except for the following:
torch.nn.ParameterContainer classes in torch.nn (e.g., Module, ModuleList, Sequential, etc.)
The torch.optim.Optimizer base class
CELoss 和 AdamW 优化器,以及余弦退火调度器;
训练循环相关逻辑,如 dataloader 以及 checkpoint 的读取/保存。
并且在 TinyStories 和 OpenWebText 两个数据集上进行大量对比/消融实验并分析结果。
我的实现放在 Cgfyufsygsm/CS336-assignment1-basics ,供参考学习使用,请勿直接抄袭否则可能啥也没学到x
我花在这个 lab 上的时间粗略估计有至少 20+ 小时,想要尽可能自己实现所有内容是相当费劲的但也能让人对 LLM 的整个基本原理有更深入的理解。我也得以亲自搭一遍 Transformer 的完整结构并实现如 tokenizer 和 text generation 相关看似不核心但仍然很重要的逻辑。
目前我对 resource accounting 相关的计算的正确性仍然不是特别有把握,如有错误欢迎随时批评指正,不胜感激!
这部分是我认为这个 lab 最难的一部分,因为实现的方案完全由自己指定,而在处理大数据集的时候会不可避免地遇到性能问题。事实上这个 lab 最花时间的部分可能正是性能优化的部分。
(a) Unicode NULL 字符(U+0000)
(b) 转义字符 \x00,打印出来是不可见字符
© 出现在文本里面的话单纯是一个不可见字符
(a) UTF-8 完全兼容 ASCII 字符,编码更紧凑,更省空间。UTF16/32 占用空间更多且引入大量高位 0 字节,浪费序列长度,增加冗余噪声。
(b) “你好”即可(包含非 ASCII 字符)。因为这个函数是逐字节解码的,但是一个 Unicode 字符在 UTF-8 表示下可能不止需要一个字节来表示,所以会出现问题。
© 0xC0 0x80 就不能被解码到任何 Unicode 字符上。
可以参考 Chen571428/cs336-assignment1-basics 的实现,其通过极致优化达到了极高的吞吐率。
这方面非常需要精细实现,好和差的实现可能效率差上几百上千倍,进而几乎无法处理 owt_train.txt 这种大达 11GB 的训练数据。几个比较关键的地方:
pretokenization 的并行化
BPE merge 的处理
encoding 的并行化
完事了之后需要把这些训练数据都转成 numpy 格式的 token 序列并保存起来以供后文的 TransformerLM 使用。
一些我遇到的坑:
merge 和 vocab 最好都把对应的字节串用某种方式(我用的是 GPT-2 使用的 encoding 方式)转成 UTF-8 可见字符然后以 json 格式输出,这样可以避免很多问题。开过多的进程反而可能带来很多额外开销,得不偿失。
可以使用 rich 库来进行日志/进度条处理,效果很好。
接下来的部分就比较简单一些了,虽然工作量不算小,但至少如果能过测试点则说明大概率没有什么问题。
建议先仔细阅读文档 15-18 页对于 batched matmul 和 einops 的解释。虽然我的实现里没有使用 einops 但这种优雅的 self-documenting 实现还是值得学习的。
以及关于行向量还是列向量的处理,我的理解是线性代数里面使用列向量是更符合数学直觉(教科书里面一般也这样),但实现的时候使用行向量形式,一是因为 memory ordering 二是因为 batch 的存在,前者天然更适合 batch 化(当然如果使用 einsum 是不是好像就完全不用 care 了)。
实现一个不带 bias 的线性层。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Linear (nn.Module):def __init__ (self, in_features, out_features, device=None , dtype=None ):super ().__init__()def _init_weight (self ):2.0 / (self.in_features + self.out_features))3 *sigma, b=3 *sigma)def forward (self, x ):return x @ self.weight.T
几个细节:
__init__ 里面要调用 super().__init__() 把 Module 给进行初始化。W 的维度应该是 (out, in),这样对应着 y = x W ⊤ y = xW^\top y = x W ⊤ (in, out) 然后 y = W x y = Wx y = W x x x x (B1, B2, in),我们想获得 (B1, B2, out) 那自然是 y = x W ⊤ y = xW^\top y = x W ⊤
Transformer 的第一层,把整数 token 给映射到向量空间。相当于若输入是 (B, T, V)(这里的 T T T V V V (B,T,D)(其中 D D D
于是用一个 V × D V\times D V × D
1 2 3 4 5 6 7 8 9 10 11 12 13 class Embedding (nn.Module):def __init__ (self, num_embeddings, embedding_dim, device=None , dtype=None ):super ().__init__()def _init_weight (self ):1 , a=-3 , b=3 ) def forward (self, x ):return self.weight[x]
现在广泛使用的 normalize 函数。对于 a ∈ R d model a\in \mathbb{R}^{d_{\text{model}}} a ∈ R d model
RMSNorm ( a i ) = a i RMS ( a ) g i \text{RMSNorm}(a_i) = \frac{a_i}{\text{RMS}(a)}g_i
RMSNorm ( a i ) = RMS ( a ) a i g i
其中 RMS ( a ) = 1 d model ∑ i = 1 d model a i 2 + ε \text{RMS}(a) = \sqrt{\frac{1}{d_{\text{model}}}\sum_{i=1}^{d_{\text{model}}}a_i^2+\varepsilon} RMS ( a ) = d model 1 ∑ i = 1 d model a i 2 + ε g i g_i g i
1 2 3 4 5 6 7 8 9 10 11 12 class RMSNorm (nn.Module):def __init__ (self, d_model: int , eps: float = 1e-5 , device=None , dtype=None ):super ().__init__()def forward (self, x ):1 , keepdim=True ) + self.eps)return ((x / rms) * self.gain).to(in_dtype)
原始 Transformer 论文使用的 FFN 是 W 2 ( ReLU ( W 1 x ) ) W_2(\text{ReLU}(W_1x)) W 2 ( ReLU ( W 1 x ) )
FFN ( x ) = SwiGLU ( x , W 1 , W 2 , W 3 ) = W 2 ( SiLU ( W 1 x ) ⊙ W 3 x ) \text{FFN}(x) = \text{SwiGLU}(x, W_1,W_2,W_3) = W_2(\text{SiLU}(W_1x) \odot W_3x)
FFN ( x ) = SwiGLU ( x , W 1 , W 2 , W 3 ) = W 2 ( SiLU ( W 1 x ) ⊙ W 3 x )
注意到为了维持参数量一致,一般 d ff = 8 3 d model d_{\text{ff}} = \frac 83 d_{\text{model}} d ff = 3 8 d model
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def SiLU (x: torch.Tensor ) -> torch.Tensor:""" Given an input tensor `x`, return the SiLU activation applied elementwise. SiLU(x) = x * sigmoid(x) """ return x * torch.sigmoid(x)class SwiGLU (nn.Module):def __init__ (self, d_model: int , d_ff: int , device=None , dtype=None ):super ().__init__()def forward (self, x: torch.Tensor ) -> torch.Tensor:return self.linear2(gate * value)
这是相对不太好写的一部分。
要做的事情是把一个 d k d_k d k 0 / 1 , 2 / 3 , ⋯ 0/1, 2/3, \cdots 0 / 1 , 2 / 3 , ⋯ i i i ω i = Θ − 2 i / d k \omega_i = \Theta^{-2i/d_k} ω i = Θ − 2 i / d k p p p ϕ p , i = p ⋅ w i \phi_{p,i} = p\cdot w_i ϕ p , i = p ⋅ w i
实现的时候,在 __init__ 里将 sin , cos \sin, \cos sin , cos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class RotaryPositionalEmbedding (nn.Module):def __init__ (self, theta: float , d_k: int , max_seq_len: int , device=None ):super ().__init__()assert (d_k % 2 == 0 ), "d_k must be even for Rotary Positional Embedding." 2 pow (theta, -2 * k / d_k)None ] * inv_freq[None , :]"cos_cached" , cos_cached, persistent=False )"sin_cached" , sin_cached, persistent=False )
half 为子空间的对数,然后 k = torch.arange(half) 再 inv_freq = torch.pow(theta, -2 * k / d_k) 得到所有的 d k / 2 d_k/2 d k / 2 w i w_i w i arange 出所有的 positions,对于 ϕ p , i \phi_{p,i} ϕ p , i angle = positions[:, None] * inv_freq[None, :],再求出相应的 sin_cached 和 cos_cached(维度均为 (max_seq_len, half))。用 register_buffer 说明它不会被更新,persistent=False 说明不会被保存进 state_dict。
现在回忆一下对于 ( x even , x odd ) ⊤ (x_{\text{even}}, x_{\text{odd}})^\top ( x even , x odd ) ⊤
( cos θ − sin θ sin θ cos θ ) ( x 0 x 1 ) = ( x 0 cos θ − x 1 sin θ x 0 sin θ + x 1 cos θ ) \begin{pmatrix}
\cos\theta& -\sin\theta\\
\sin\theta & \cos \theta
\end{pmatrix}\begin{pmatrix}
x_0\\x_1
\end{pmatrix} = \begin{pmatrix}
x_0\cos\theta - x_1\sin\theta\\
x_0\sin\theta + x_1\cos\theta
\end{pmatrix}
( cos θ sin θ − sin θ cos θ ) ( x 0 x 1 ) = ( x 0 cos θ − x 1 sin θ x 0 sin θ + x 1 cos θ )
1 2 3 4 5 6 7 8 9 10 def forward (self, x: torch.Tensor, token_positions: torch.Tensor ) -> torch.Tensor:1 ], -1 , 2 )0 ]1 ]getattr (self, "cos_cached" )[token_positions]getattr (self, "sin_cached" )[token_positions]1 )return x_pair.view(*x.shape[:-1 ], self.d_k)
注意这里的 token_positions 是给定的,不一定是完整的 0 , 1 , ⋯ 0,1,\cdots 0 , 1 , ⋯
首先用 view 把奇偶维度切开,此时的 x_even 和 x_odd 维度为 (..., seq_len, half),token_positions 维度为 (..., seq_len)。
然后把对应位置的 cos 和 sin 给取出来,取出来的 cos_pos 维度为 (..., half)。然后就可以算新的 x_even 和 x_odd 了。最后 stack 起来再还原维度成 d_k 即可。
首先需要实现 softmax,需要在指定的维度进行 softmax,并把所有的项减去 max \max max
1 2 3 4 5 6 def softmax (x: torch.Tensor, dim: int ) -> torch.Tensor:""" Given an input tensor `x`, return the softmax applied along dimension `dim`. """ max (x, dim=dim, keepdim=True ).values)return exp_x / torch.sum (exp_x, dim=dim, keepdim=True )
然后实现
Attention ( Q , K , V ) = softmax ( Q ⊤ K d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{Q^\top K}{\sqrt{d_k}}\right)V
Attention ( Q , K , V ) = softmax ( d k Q ⊤ K ) V
同时需要实现 masking。输入一个 (seq_len, seq_len) 的 mask,如果 mask[i, j] == False 说明 query i i i j j j
首先明确一下这个函数的维度:
1 2 3 4 5 6 7 Args:Float [Tensor, " ... queries d_k"]): Query tensorFloat [Tensor, " ... keys d_k"]): Key tensorFloat [Tensor, " ... values d_v"]): Values tensor| None ): Mask tensorReturns :Float [Tensor, " ... queries d_v"]: Output of SDPA
实现的时候显然没法直接写 Q ⊤ K Q^\top K Q ⊤ K (..., queries keys) 的([i, j] 表示 how query i i i j j j values 一般应当等于 keys)所以应当写成 score = q @ k.transpose(-2, -1),即把 K K K
完整代码如下,剩下的都不难,mask 可以直接在 softmax 之前把被 mask 住的地方赋 − inf -\inf − inf
1 2 3 4 5 6 7 8 def scaled_dot_product_attention (q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, mask: torch.Tensor | None = None ):1 ]2 , -1 )if mask is not None :1 )return attn @ v
需要实现一个带 mask 的多头注意力机制并且使用 RoPE。
这里我的实现是将 RoPE 作为构造函数的参数直接传进来。
输入是 (..., seq_len, d_model) 的,要把 x x x h h h h h h W Q , W K ∈ R h d k × d model , W V ∈ R h d v × d model W_Q,W_K\in \mathbb{R}^{hd_k\times d_{\text{model}}},W_V\in\mathbb{R}^{hd_v\times d_{\text{model}}} W Q , W K ∈ R h d k × d model , W V ∈ R h d v × d model h h h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class MultiheadSelfAttention (nn.Module):def __init__ (self, d_model: int , num_heads: int , rope: RotaryPositionalEmbedding | None = None ):super ().__init__()assert d_model % num_heads == 0 def forward (self, x: torch.Tensor, token_positions: torch.Tensor | None = None ) -> torch.Tensor:1 ], self.num_heads, self.head_dim).transpose(-3 , -2 ).contiguous() 1 ], self.num_heads, self.head_dim).transpose(-3 , -2 ).contiguous() 1 ], self.num_heads, self.head_dim).transpose(-3 , -2 ).contiguous() 2 ], x.shape[-2 ]), dtype=torch.bool , device=x.device)) if self.rope is not None :if token_positions is None :2 ], device=x.device)3 , -2 ).contiguous() 2 ], self.d_model) return output
y = x + MultiHeadSelfAttention ( RMSNorm ( x ) ) y = x + \text{MultiHeadSelfAttention}(\text{RMSNorm}(x))
y = x + MultiHeadSelfAttention ( RMSNorm ( x ) )
实现一个 pre-norm 结构的 Transformer Block。没什么好说的直接套娃之前的就行了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class TransformerBlock (nn.Module):def __init__ (self, d_model: int , num_heads: int , d_ff: int , theta: float = 100000.0 , max_seq_len: int = 2048 ):""" d_model: int Dimensionality of the Transformer block inputs. num_heads: int Number of heads to use in multi-head self-attention. d_ff: int Dimensionality of the position-wise feed-forward inner layer. """ super ().__init__()def forward (self, x: torch.Tensor ):return y + self.ffn(self.norm2(y))
最后把他们都套起来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class TransformerLM (nn.Module):def __init__ (self, d_model: int , num_heads: int , d_ff: int , vocab_size: int , context_length: int , num_layers: int , rope_theta: float = 100000.0 ):super ().__init__()for _ in range (num_layers)])def forward (self, x: torch.Tensor ):return x
统计参数量和 FLOPS。计算方法:对于 A ∈ R m × n , B ∈ R n × p A\in \mathbb{R}^{m\times n}, B\in \mathbb{R}^{n\times p} A ∈ R m × n , B ∈ R n × p 2 m n p 2mnp 2 m n p
对于 GPT-2 XL,如下参数:
1 2 3 4 5 6 vocab_size: 50257 context_length: 1024 num_layers: 48 d_model: 1600 num_heads: 25 d_ff: 6400
可训练的参数数量:
embedding 和 output linear 各 V × d V\times d V × d
对于每层 Transformer block:
W Q , W K , W V , W O W_Q,W_K,W_V,W_O W Q , W K , W V , W O 4 d 2 4d^2 4 d 2 这里的 d ff d_{\text{ff}} d ff 4 d 4d 4 d 2 d ⋅ d ff 2d\cdot d_{\text{ff}} 2 d ⋅ d ff
两个 RMSNorm 有 2 d 2d 2 d
output RMSNorm 有一个 d d d
所以一共是 2 V d + N ( 4 d 2 + 2 d d ff + 2 d ) + d = 2 V d + N ( 12 d 2 + 2 d ) + d 2Vd+N(4d^2+2dd_{\text{ff}}+2d)+d=2Vd+N(12d^2+2d)+d 2 V d + N ( 4 d 2 + 2 d d ff + 2 d ) + d = 2 V d + N ( 1 2 d 2 + 2 d ) + d 2 V d + N ( 4 d 2 + 2 d ⋅ d f f + 2 d ) + d = 2 V d + N ( 12 d 2 + 2 d ) + d 2Vd + N(4d^2 + 2d\cdot d_{ff} + 2d) + d = 2Vd+N(12d^2+2d)+d 2 V d + N ( 4 d 2 + 2 d ⋅ d f f + 2 d ) + d = 2 V d + N ( 1 2 d 2 + 2 d ) + d
计算一次前向传播的 FLOPs
设 context_length 为 L L L
Q/K/V 投影:3 次 ( L × d ) ⋅ ( d × d ) (L\times d)\cdot(d\times d) ( L × d ) ⋅ ( d × d ) 6 L d 2 6 L d^2 6 L d 2
O 投影:1 次 ( L × d ) ⋅ ( d × d ) (L\times d)\cdot (d\times d) ( L × d ) ⋅ ( d × d ) 2 L d 2 2 L d^2 2 L d 2
注意力分数:Q K ⊤ QK^\top Q K ⊤ ( L × d ) ⋅ ( d × L ) (L\times d)\cdot (d\times L) ( L × d ) ⋅ ( d × L ) 2 L 2 d 2 L^2 d 2 L 2 d
注意力加权:Attn ⋅ V \text{Attn}\cdot V Attn ⋅ V ( L × L ) ⋅ ( L × d ) (L\times L)\cdot (L\times d) ( L × L ) ⋅ ( L × d ) 2 L 2 d 2 L^2 d 2 L 2 d
FFN:2 L d d ff × 2 2 L d d_{\text{ff}}\times 2 2 L d d ff × 2 4 L d d ff 4 L d d_{\text{ff}} 4 L d d ff
所以一层的是 8 L d 2 + 4 L 2 d + 4 L d d f f = 24 L d 2 + 4 L 2 d 8Ld^2 + 4L^2d + 4Ldd_{ff} = 24Ld^2 + 4L^2d 8 L d 2 + 4 L 2 d + 4 L d d f f = 2 4 L d 2 + 4 L 2 d
输出线性:( L × d ) ⋅ ( d × V ) (L\times d)\cdot (d\times V) ( L × d ) ⋅ ( d × V ) 2 L d V 2 L d V 2 L d V
所以是 N ( 24 L d 2 + 4 L 2 d ) + 2 L d V N(24Ld^2+4L^2d)+2LdV N ( 2 4 L d 2 + 4 L 2 d ) + 2 L d V
分析哪部分需要最多的 FLOPs
FFN 占约 57.4%,最大;注意力投影约 28.7%;注意力分数/加权约 9.2%;输出线性约 4.7%。
假设 GPT‑2 small/medium/large 都是 d_ff=4*d_model,且 L = 1024 , V = 50257 L=1024, V=50257 L = 1 0 2 4 , V = 5 0 2 5 7
模型
Attn proj
Attn inner
FFN
LM head
GPT-2 small (12L, d=768, h=12)
19.88%
13.25%
39.76%
27.10%
GPT-2 medium (24L, d=1024, h=16)
24.93%
12.47%
49.86%
12.75%
GPT-2 large (36L, d=1280, h=20)
27.23%
10.89%
54.46%
7.42%
GPT-2 XL (48L, d=1600, h=25)
28.71%
9.19%
57.41%
4.70%
随着模型变大,d 2 d^2 d 2 L 2 d L^2 d L 2 d L d V L~d~V L d V
GPT‑2 XL 把 L L L L 2 L^2 L 2 L L L
Transformer 对于 (B, seq_len) 的 token 输入,输出的 logits 是 (B, seq_len, vocab_size) 的,相当于是“每个位置上的 next-token prediction”。那么监督信号自然是用输出的 logits 和真实的 target 做 cross-entropy loss。具体地来看就是文档里的
l i = − log softmax ( o i ) [ x i + 1 ] = − log exp ( o i [ x i + 1 ] ) ∑ a = 1 vocab_size exp ( o i [ a ] ) l_i = -\log \text{softmax}(o_i)[x_{i+1}] = -\log\frac{\exp(o_i[x_{i+1}])}{\sum_{a=1}^{\texttt{vocab\_size}}\exp(o_i[a])}
l i = − log softmax ( o i ) [ x i + 1 ] = − log ∑ a = 1 vocab_size exp ( o i [ a ] ) exp ( o i [ x i + 1 ] )
文档里说要考虑数值稳定性,避免不必要的 log \log log exp \exp exp o o o max \max max z z z
− log exp ( o i [ x i + 1 ] ) ∑ a = 1 vocab_size exp ( o i [ a ] ) = log ∑ a = 1 vocab_size exp ( z i [ a ] ) − z i [ x i + 1 ] -\log\frac{\exp(o_i[x_{i+1}])}{\sum_{a=1}^{\texttt{vocab\_size}}\exp(o_i[a])} = \log\sum_{a=1}^{\texttt{vocab\_size}}\exp(z_i[a]) - z_i[x_{i+1}]
− log ∑ a = 1 vocab_size exp ( o i [ a ] ) exp ( o i [ x i + 1 ] ) = log a = 1 ∑ vocab_size exp ( z i [ a ] ) − z i [ x i + 1 ]
1 2 3 4 5 6 def CrossEntropyLoss (input : torch.Tensor, target: torch.Tensorinput - input .max (dim=-1 , keepdim=True ).values1 , keepdim=True )1 , index=target.unsqueeze(-1 )).squeeze(-1 )return loss
因为取 z_true 是想要 z[i, target_i] 所以这里需要用 gather。
文档让我们尝试调整 SGD 的 learning rate。发现 1e1 收敛过慢,1e2 正好,1e3 loss 直接爆炸了。
实现是简单的,直接依葫芦画瓢就行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class AdamW (torch.optim.Optimizer):def __init__ (self, params, lr=1e-3 , betas=(0.9 , 0.999 1e-8 , weight_decay=0.01 ):if lr < 0.0 :raise ValueError(f"Invalid learning rate: {lr} " )if not 0.0 <= betas[0 ] < 1.0 :raise ValueError(f"Invalid beta parameter at index 0: {betas[0 ]} " )if not 0.0 <= betas[1 ] < 1.0 :raise ValueError(f"Invalid beta parameter at index 1: {betas[1 ]} " )if eps < 0.0 :raise ValueError(f"Invalid epsilon value: {eps} " )if weight_decay < 0.0 :raise ValueError(f"Invalid weight_decay value: {weight_decay} " )dict (lr=lr, betas=betas, eps=eps, weight_decay=weight_decay)super ().__init__(params, defaults)def step (self, closure: Optional [Callable ]=None ):None if closure is None else closure()for group in self.param_groups:"lr" ]"betas" ]"eps" ]"weight_decay" ]for p in group["params" ]:if p.grad is None :continue if len (state) == 0 :"t" ] = 0 "m" ] = torch.zeros_like(p.data)"v" ] = torch.zeros_like(p.data)"m" ] = beta1 * state["m" ] + (1 - beta1) * grad"v" ] = beta2 * state["v" ] + (1 - beta2) * (grad ** 2 )"t" ] += 1 "t" ]1 - beta2 ** t) / (1 - beta1 ** t)"m" ] / (torch.sqrt(state["v" ]) + eps)return loss
Resource accounting:
(a) 分析如下:
参数量见上,P = 2 V d + N ( 12 d 2 + 2 d ) + d P = 2Vd + N(12d^2+2d)+d P = 2 V d + N ( 1 2 d 2 + 2 d ) + d M param = 4 P M_{\text{param}} = 4P M param = 4 P
每个参数一个梯度,M grad = 4 P M_{\text{grad}} = 4P M grad = 4 P
Adam 维护两个动量,M opt = 8 P M_{\text{opt}} = 8P M opt = 8 P
Activations:
每层 Transformer block:
RMSNorm × 2 \times 2 × 2 2 B L d 2BLd 2 B L d
QKV project:3 B L d 3BLd 3 B L d
Q K ⊤ QK^\top Q K ⊤ B h L 2 BhL^2 B h L 2 softmax 输出:B h L 2 BhL^2 B h L 2
加权求和输出: B L d BLd B L d
最终投影:B L d BLd B L d
FFN:B L d f f + B L d f f + B L d BLd_{ff} + BLd_{ff} + BLd B L d f f + B L d f f + B L d
所以 A layer = 16 B L d + 2 B h L 2 A_{\text{layer}} = 16BLd+2BhL^2 A layer = 1 6 B L d + 2 B h L 2
final RMSNorm:B L d BLd B L d
output logits:B L V BLV B L V
CELoss:B L V BLV B L V
所以总共是 A = N ( 16 B L d + 2 B h L 2 ) + B L d + 2 B L V A = N(16BLd+2BhL^2)+BLd+2BLV A = N ( 1 6 B L d + 2 B h L 2 ) + B L d + 2 B L V
M act = 4 A M_{\text{act}} = 4A M act = 4 A
峰值显存为 M peak = 16 P + 4 A M_{\text{peak}} = 16P + 4A M peak = 1 6 P + 4 A
(b) 代入数据计算即可,解得 B max = 3 B_{\max} = 3 B m a x = 3
© 3 B ( L ( 24 L d 2 + 4 L 2 d ) + 2 L d V ) + Θ ( P ) 3B(L(24Ld^2+4L^2d)+2LdV) + \Theta(P) 3 B ( L ( 2 4 L d 2 + 4 L 2 d ) + 2 L d V ) + Θ ( P )
Forward FLOPS:只考虑 matmul,则:F fwd = B ( L ( 8 L d 2 + 4 L 2 d + 4 L d d f f ) + 2 L d V ) = B ( L ( 24 L d 2 + 4 L 2 d ) + 2 L d V ) F_{\text{fwd}} = B(L(8Ld^2+4L^2d+4Ldd_{ff})+2LdV) = B(L(24Ld^2+4L^2d)+2LdV) F fwd = B ( L ( 8 L d 2 + 4 L 2 d + 4 L d d f f ) + 2 L d V ) = B ( L ( 2 4 L d 2 + 4 L 2 d ) + 2 L d V )
Backward FLOPS:近似两倍 2 F fwd 2F_{\text{fwd}} 2 F fwd F adam = Θ ( P ) F_{\text{adam}} = \Theta(P) F adam = Θ ( P )
(d) 每 step 的 FLOPS:3 × 1024 × ( L ( 24 L d 2 + 4 L 2 d ) + 2 L d V ) ≈ 1.08 × 1 0 16 3\times 1024 \times (L(24Ld^2+4L^2d)+2LdV) \approx 1.08\times 10^{16} 3 × 1 0 2 4 × ( L ( 2 4 L d 2 + 4 L 2 d ) + 2 L d V ) ≈ 1 . 0 8 × 1 0 1 6 400 400 4 0 0 t = F total 19.5 × 50 % = 4.419 × 1 0 8 t = \frac{F_{\text{total}}}{19.5\times 50\%} = 4.419\times 10^8 t = 1 9 . 5 × 5 0 % F total = 4 . 4 1 9 × 1 0 8
文档里要求使用 LLaMA 的余弦退火。
即先 warm-up,然后 cosine,最后维持 min lr。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def lr_cosine_schedule ( it: int , max_learning_rate: float , min_learning_rate: float , warmup_iters: int , cosine_cycle_iters: int , if it < warmup_iters:elif it <= cosine_cycle_iters:0.5 * (max_learning_rate - min_learning_rate) * (1 + math.cos(math.pi * (it - warmup_iters) / (cosine_cycle_iters - warmup_iters)))else :return lr
限制梯度的 L2-Norm 不要太大避免梯度爆炸:
1 2 3 4 5 6 7 8 9 def gradient_clipping (parameters: Iterable[torch.nn.Parameter], max_l2_norm: float ):1e-6 for p in parameters:if p.grad is None :continue 2 )if param_norm > max_l2_norm:
根据文档的说法直接弄就行,相当于随机 sample batch_size 个 start 点,然后往后找 context_length 这么长的数据。一起返回就好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def get_batch ( dataset: np.ndarray, batch_size: int , context_length: int , device: str , tuple [torch.Tensor, torch.Tensor]:""" Sample language modeling batches from a 1D token ID array. Returns: Tuple of LongTensors (x, y) with shape (batch_size, context_length). """ if dataset.ndim != 1 :raise ValueError("dataset must be a 1D numpy array of token IDs" )len (dataset) - context_lengthif max_start <= 0 :raise ValueError("dataset length must be greater than context_length" )0 , max_start, size=batch_size)for i in starts], axis=0 )1 : i + context_length + 1 ] for i in starts], axis=0 )return x, y
利用好 torch 的 state_dict() 就可以了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import torchimport osimport typingdef save_checkpoint ( model: torch.nn.Module, optimizer: torch.optim.Optimizer, iteration: int , out: str | os.PathLike | typing.BinaryIO | typing.IO[bytes ] "model_state_dict" : model.state_dict(),"optimizer_state_dict" : optimizer.state_dict(),"iteration" : iteration,def load_checkpoint ( src: str | os.PathLike | typing.BinaryIO | typing.IO[bytes ], model: torch.nn.Module, optimizer: torch.optim.Optimizer "model_state_dict" ])"optimizer_state_dict" ])return state["iteration" ]
这个每个人写的脚本都不尽相同,主要提几个点:
每个 it 的循环内,先用余弦退火算出 lr,然后设置 optimizer 里面的 lr;然后用之前写的 get_batch sample 出这一轮需要的 batch,调用 model(x) 算出 logits,再计算 loss;然后 loss.backward(),梯度裁剪,再 optimizer.step() 更新参数。
在合适的时候 log/保存 checkpoint 即可。
涉及到的参数可能巨多无比,需要想一下怎么管理参数。我的做法是用一个 config.py 来维护,然后可以在命令行里面传参进行覆盖。
我们生成文字的时候是自回归(autoregressive)式的生成,每次喂进去已有的序列,然后获得下一个 token 的概率分布并 sample 之。具体地即
P ( x t + 1 = i ∣ x 1 , ⋯ , t ) = exp ( v i ) ∑ j exp ( v j ) v = TransformerLM ( x 1 , ⋯ , t ) t ∈ R vocab_size \begin{aligned}
P(x_{t+1}=i \mid x_{1,\cdots,t}) &= \frac{\exp(v_i)}{\sum_j \exp(v_j)}\\
v &= \text{TransformerLM}(x_{1,\cdots,t})_t\in\mathbb{R}^{\texttt{vocab\_size}}
\end{aligned}
P ( x t + 1 = i ∣ x 1 , ⋯ , t ) v = ∑ j exp ( v j ) exp ( v i ) = TransformerLM ( x 1 , ⋯ , t ) t ∈ R vocab_size
相当于,每次喂进去的是一个长度为 seq_len \texttt{seq\_len} seq_len seq_len × vocab_size \texttt{seq\_len}\times\texttt{vocab\_size} seq_len × vocab_size <|endoftext|> \texttt{<|endoftext|>} <|endoftext|>
具体地有两个参数可以设置,一个是温度 Temperature (τ \tau τ p p p τ \tau τ τ → 0 \tau\to 0 τ → 0 V ( p ) V(p) V ( p ) ∑ j ∈ V ( p ) q j ≥ p \sum_{j\in V(p)} q_j\ge p ∑ j ∈ V ( p ) q j ≥ p q j q_j q j q i ∑ j ∈ V ( p ) q j \frac{q_i}{\sum_{j\in V(p)} q_j} ∑ j ∈ V ( p ) q j q i V ( p ) V(p) V ( p ) V ( p ) V(p) V ( p ) 0 0 0
写一个 decoding.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 import torchfrom torch import Tensorfrom cs336_basics.nn.util import softmaxdef apply_temperature (logits: Tensor, temperature: float ) -> Tensor:""" Scale logits by temperature. Lower temperature sharpens the distribution. """ if temperature <= 0 :raise ValueError("temperature must be > 0 for scaling" )return logits / temperaturedef top_p_filter (logits: Tensor, top_p: float ) -> Tensor:""" Apply nucleus (top-p) filtering to logits. Keeps the smallest set of tokens whose cumulative probability >= top_p. """ if top_p >= 1.0 :return logitsif top_p <= 0.0 :1 , keepdim=True )bool )1 , top_idx, False )return logits.masked_fill(mask, -float ("inf" ))1 )1 , descending=True )1 )1 :] = cutoff[..., :-1 ].clone()0 ] = False 1 , sorted_idx, cutoff)return logits.masked_fill(mask, -float ("inf" ))def sample_next_token ( logits: Tensor, temperature: float = 1.0 , top_p: float = 1.0 , rng: torch.Generator | None = None , """ Sample token ids from logits (shape: [batch, vocab] or [vocab]). """ False if logits.dim() == 1 :0 )True if temperature <= 0 :1 )return next_ids.squeeze(0 ) if squeeze_out else next_ids1 )1 , generator=rng).squeeze(-1 )return next_ids.squeeze(0 ) if squeeze_out else next_ids@torch.no_grad() def generate_tokens ( model: torch.nn.Module, prompt_ids: Tensor | list [int ], max_new_tokens: int , eos_id: int | None = None , temperature: float = 1.0 , top_p: float = 1.0 , context_length: int | None = None , rng: torch.Generator | None = None , """ Autoregressively generate tokens from a prompt. """ next (model.parameters()).deviceif torch.is_tensor(prompt_ids):else :False if prompt.dim() == 1 :0 )True if max_new_tokens < 0 :raise ValueError("max_new_tokens must be >= 0" )None None if eos_id is not None :0 ), device=device, dtype=torch.bool )for _ in range (max_new_tokens):if context_length is not None and generated.size(1 ) > context_length:else :1 , :]if finished is not None :1 )], dim=-1 )if finished is not None and torch.all (finished):break return generated.squeeze(0 ) if squeeze_out else generated
然后在 TransformerLM 类中实现成员函数即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @torch.no_grad() def generate ( self, prompt_ids: torch.Tensor | list [int ], max_new_tokens: int , eos_id: int | None = None , temperature: float = 1.0 , top_p: float = 1.0 , context_length: int | None = None , rng: torch.Generator | None = None , return generate_tokens(
当然别忘记最后输出的结果是 token 序列,还需要经过 tokenizer 来解码。
这个部分需要做超级多的实验,而如何管理这些实验的参数/检查点/结果则尤为重要。此时可以充分利用 AI 进行参谋。比如我在跑消融实验的时候就首先分了若干 git branch,然后分别把对应的模块更换/删除。跑的时候利用 git worktrees 把这几个工作目录隔开,然后写一个自动跑任务的脚本来实现多卡并行跑实验。
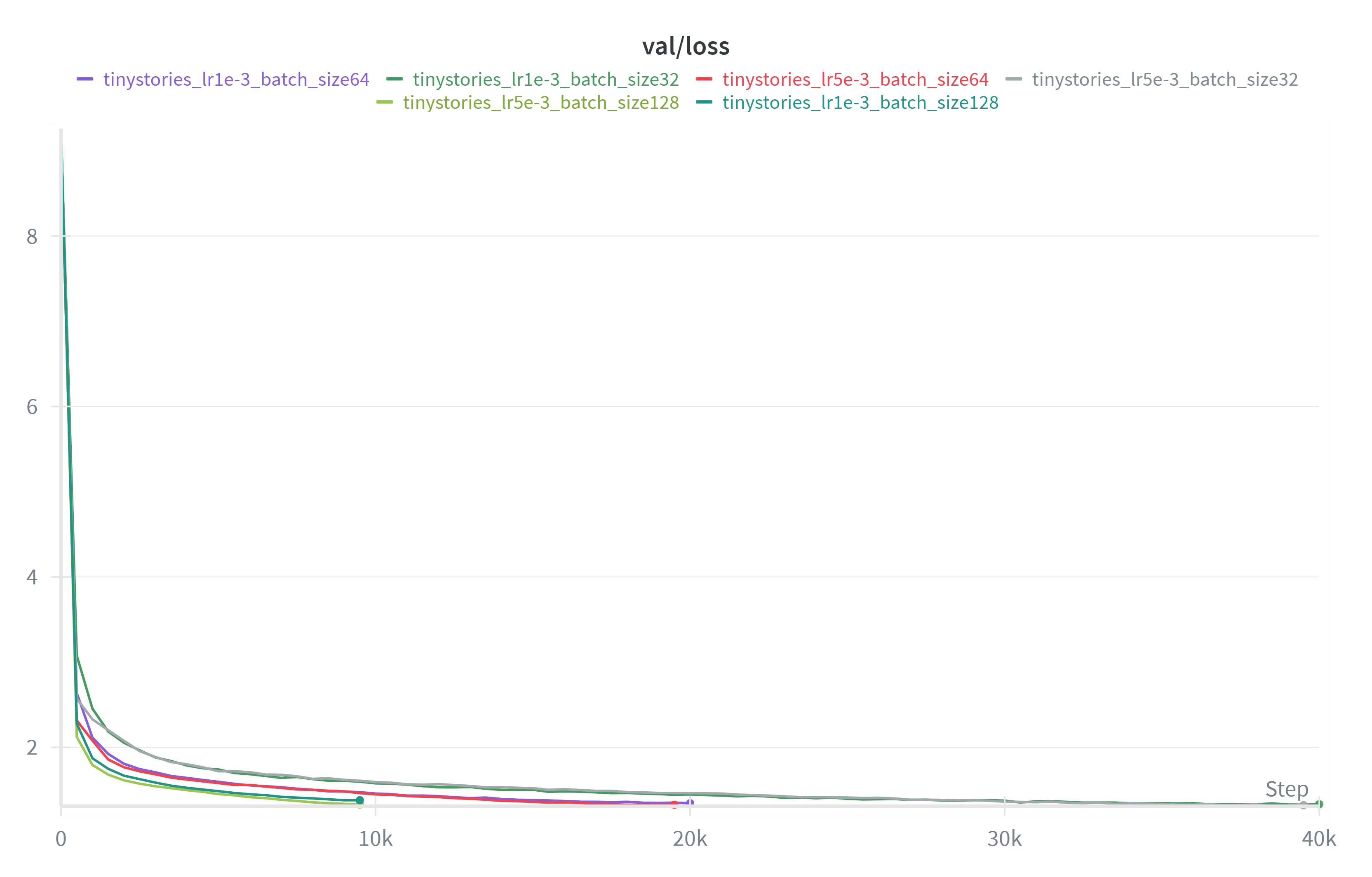
这是我对于 lr 进行的尝试。发现当 lr 为 1e-4 的时候收敛速度就相当慢,而 lr 为 1e-3 的时候最后收敛效果是最好的,validation loss 能降至 1.33 以下(低于 1.45 的 baseline)当 lr 为 5e-4 的时候收敛效果就没那么好了,而当 lr 取 1e-2 的时候训练直接发散。
发现甚至在 lr=9e-3 的时候表现都较为良好,但一到 1e-2 就发散了。
由于要确保总 token 数一样,所以不同的 bs 对应不同的训练步数。在 32 到 128 范围内改变 batch_size 并未对实验结果产生较大影响,不过 bs 取 32 的时候训练时间会略长。
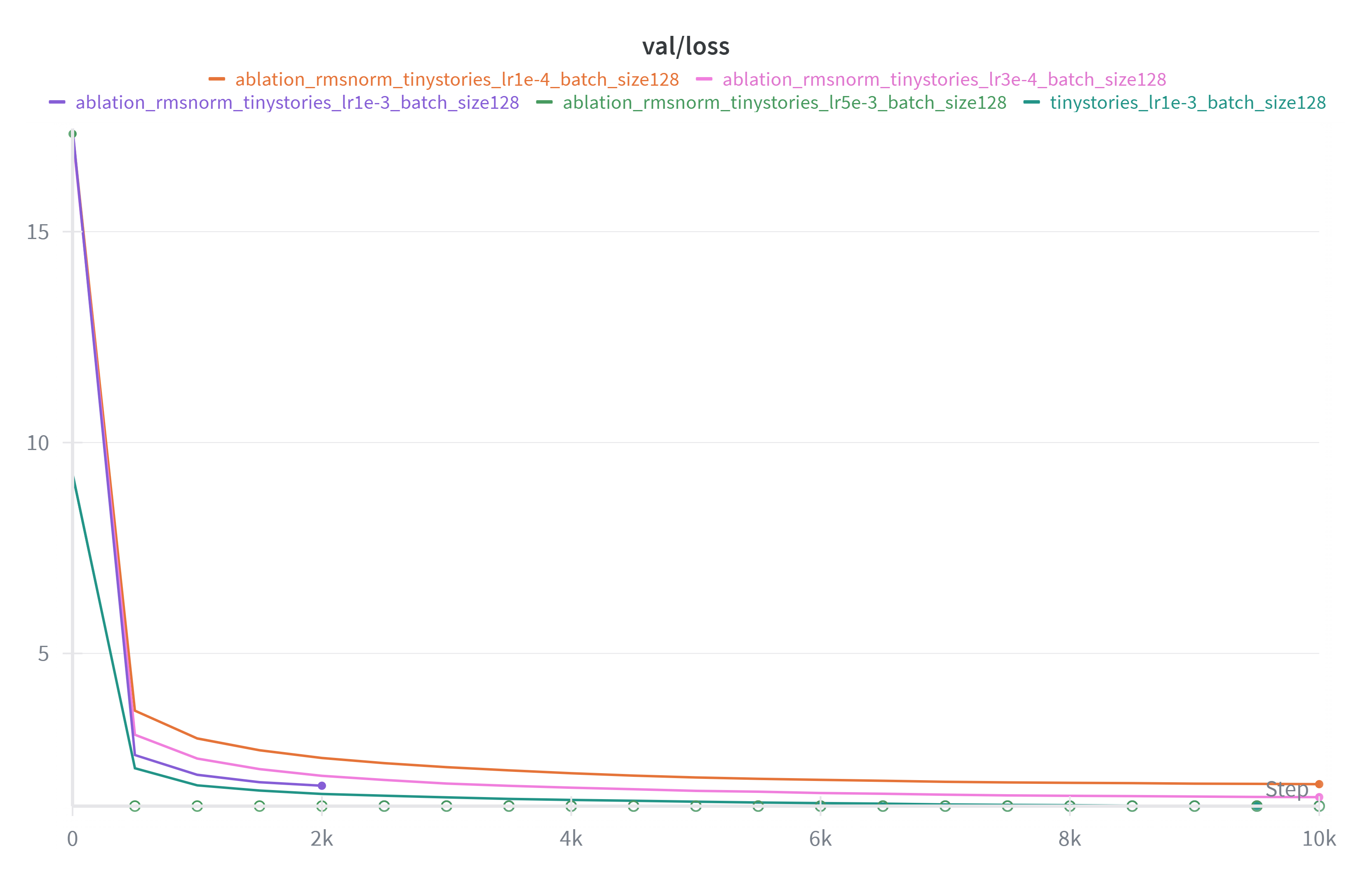
去掉 RMSNorm 后注意到对于 lr=1e-3 和 5e-3 的情况 loss 均在训练一段时间后变为 NaN。未变为 NaN 的情况训练出来效果也显著差。RMSNorm 对保持训练稳定非常重要。
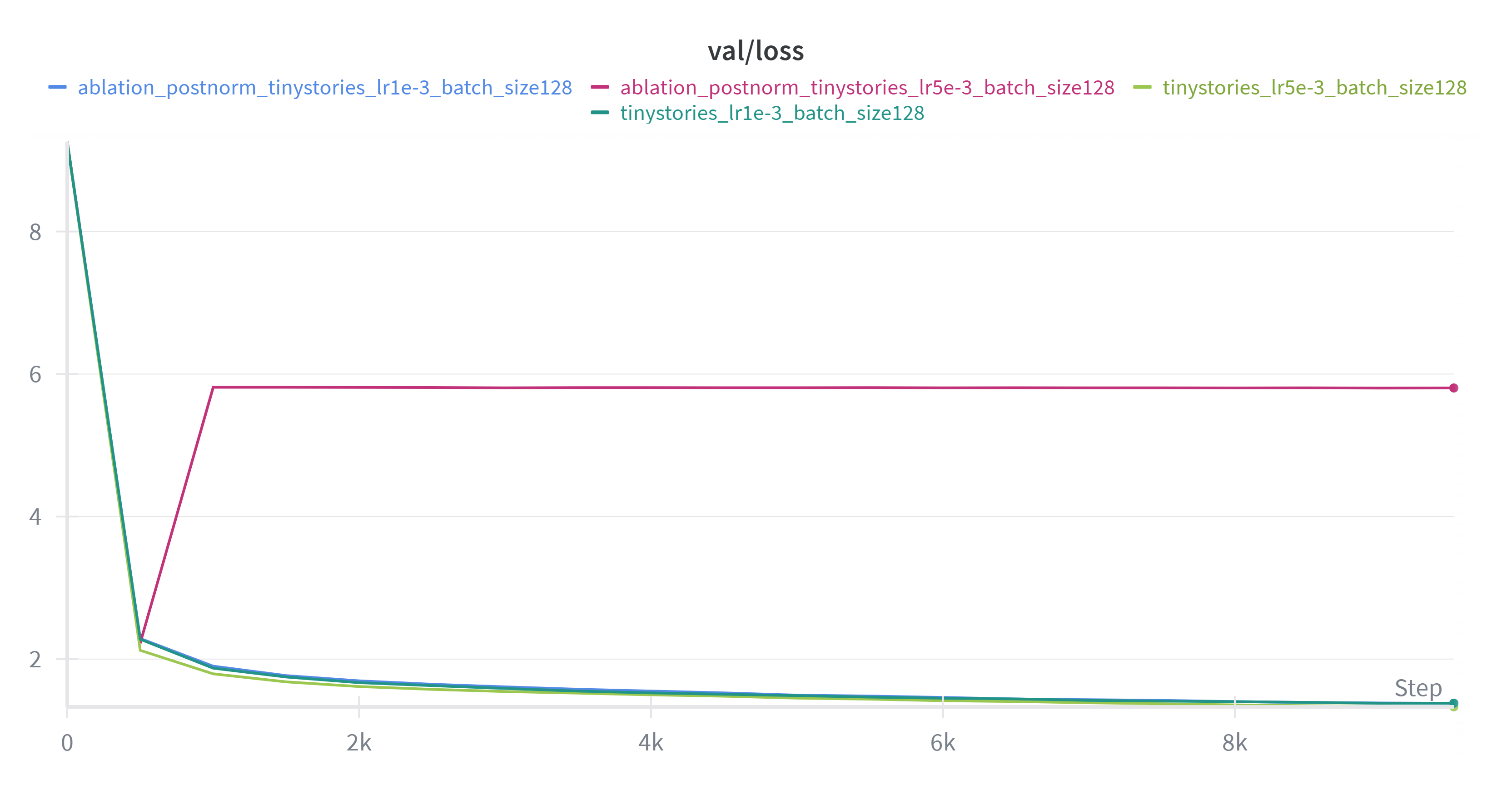
Post norm 稳定性也会变差。
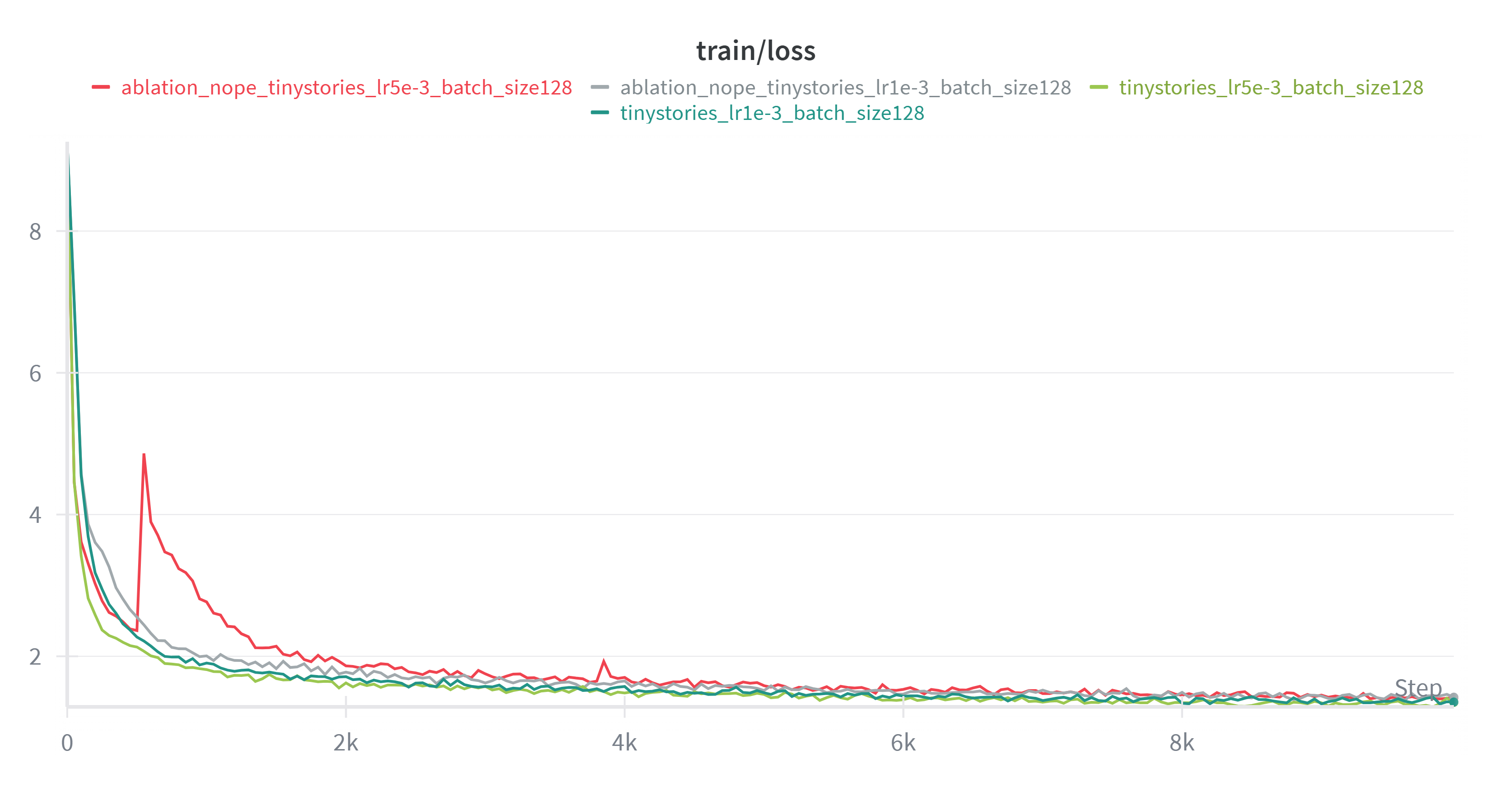
nope 在学习率高的时候可能不太稳定,且效果略差于 RoPE。差距不明显可能源于数据集和模型都比较小。
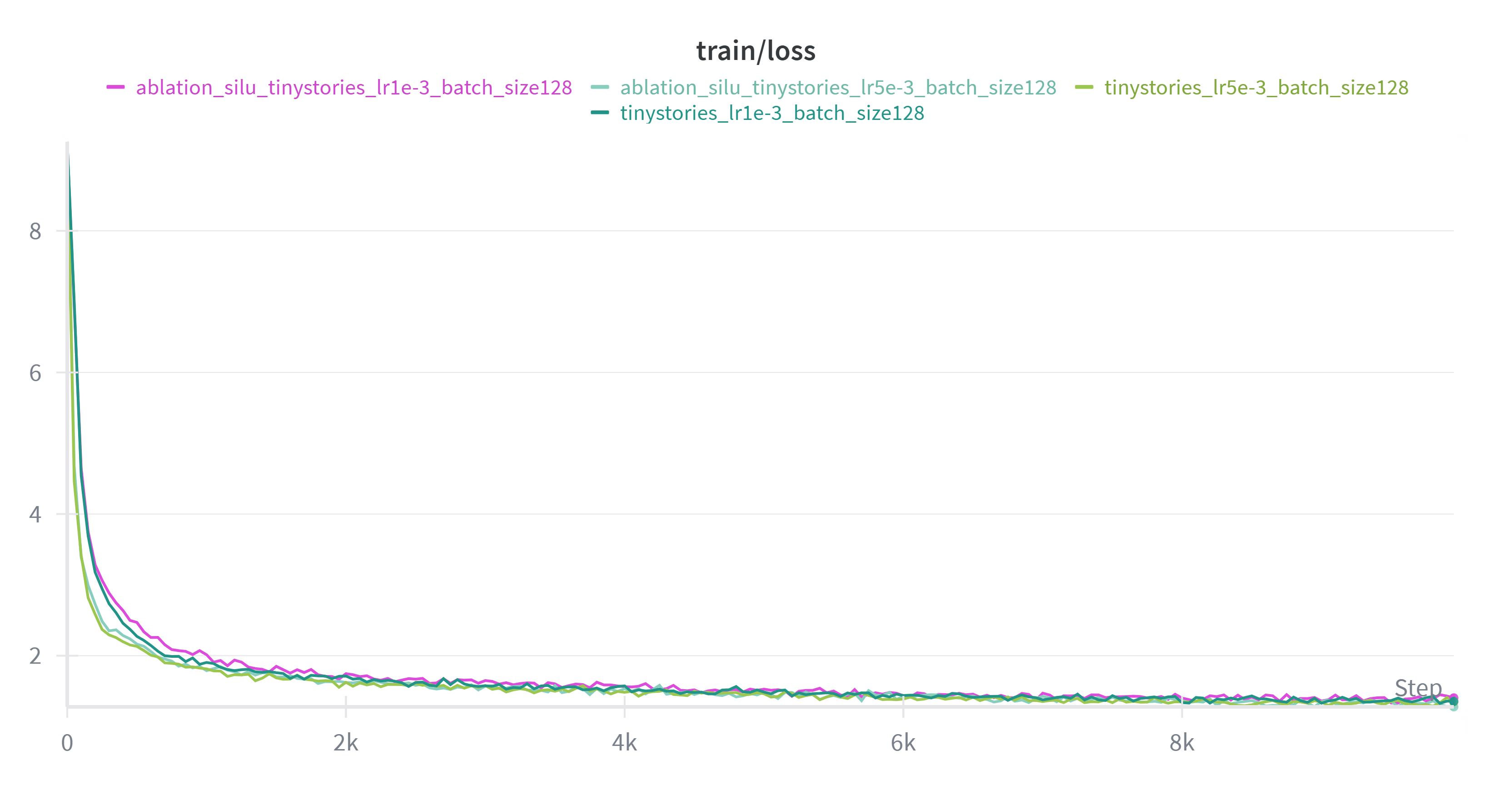
将 SwiGLU 换成 SiLU 后,收敛速度较慢。
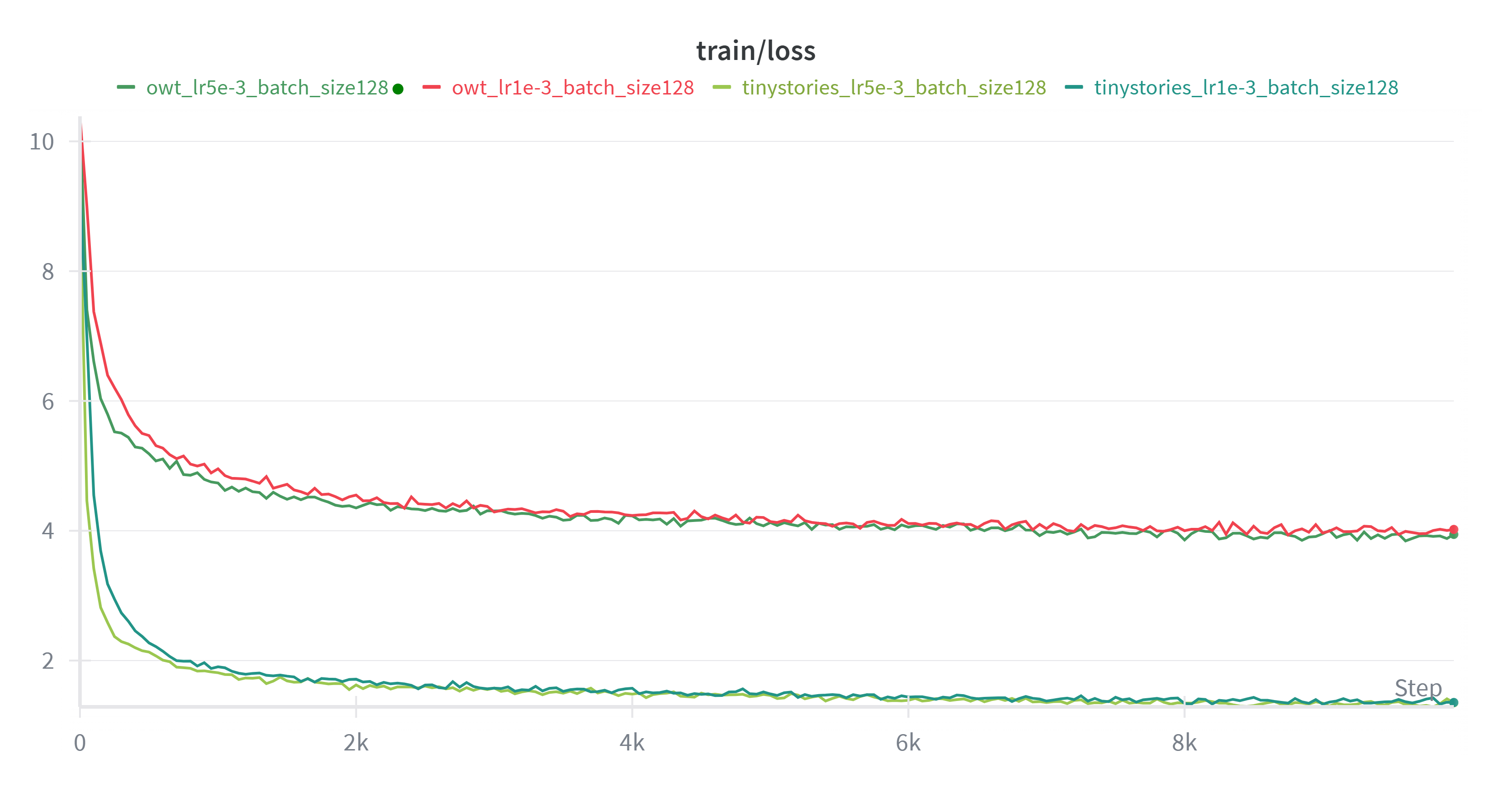
owt 上训的模型 loss 显著高于 TinyStories 上训的模型,因为后者的文本结构简单,可预测性高,而前者覆盖领域广,语言复杂, 条件熵更大,所以 loss 更高。
例子(owt):Generate a story: Now: func () { public function test.getPost(): You could use the UDP tool (application).getPost(): getPost(): ActivateAgent() protected instrument the Public response to public pronouncements. getPost(): getPost() aView specified { public inquiry into this. see
例子(ts):Generate a story: a prince was playing with her and her friends. It was a weird story! She had never heard a story before, so she never saw it before. She ran to her mom and asked, "Mom, can I bend down and be Tim?" Mom smiled and said, "You have to be careful when you
因为 TinyStories 的文本分布简单且高度集中,小模型在相同算力下就能学到稳定的叙事结构;而 owt 含有各种各样杂乱的文本,所以在同样训练规模下未能学习到有效模式,因此生成不流畅,质量差。
.png)
.png)