Last updated on February 21, 2025 10:12 PM
本文主要涉及无监督学习中的降维/聚类方法,介绍了 PCA、k-means 与 EM 算法。一键回城 。
之前我们学习的都是有监督学习,我们的目标是最小化一个损失函数 L ( f ( x ) , y ) L(f(x),y) L ( f ( x ) , y ) P ( y ∣ x ) P(y|x) P ( y ∣ x )
而无监督学习可以理解为只给一堆 X X X X X X P ( X ) P(X) P ( X )
一般有三种:
降维(dimensionality reduction):学习一个更 compact 的 f ( x ) f(x) f ( x )
聚类(clustering):将一系列具有高相似度的样本聚为一类进行分析。
生成式模型:如 ChatGPT,Diffusion 等
一种经典的降维方法,x ∈ R d → z ∈ R d ′ x\in \mathbb{R}^d \to z \in \mathbb{R}^{d'} x ∈ R d → z ∈ R d ′ d ′ < d d' < d d ′ < d
考虑数据在高维空间中分布通常是不均匀的,即在某些维度上变化比较大,而在另一些上比较小。所以我们可以把每个 x x x u 1 u_1 u 1 x x x
准则:
找到一个新的坐标系 u 1 , u 2 u_1,u_2 u 1 , u 2
要求 u 1 u_1 u 1 u 1 u_1 u 1 方差最大化 ;
迭代地寻找其他的使得剩余方差最大的 u 2 , u 3 , ⋯ u_2,u_3, \cdots u 2 , u 3 , ⋯
实际应用中有些数据可能不太满足这种线性性,用一些其他的非线性降维方法可能可以获得更好效果。
令
X = [ x 1 T x 2 T ⋮ x n T ] ∈ R n × d X = \begin{bmatrix} x_1^T \\ x_2^T \\ \vdots \\ x_n^T \\\end{bmatrix} \in \mathbb{R}^{n\times d}
X = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ x 1 T x 2 T ⋮ x n T ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ ∈ R n × d
计算均值
x ‾ = 1 n ∑ i ∈ [ n ] x i ∈ R d \overline{x} = \frac{1}{n} \sum_{i \in [n]} x_i \in \mathbb{R}^d
x = n 1 i ∈ [ n ] ∑ x i ∈ R d
数据的协方差矩阵为
Σ = 1 n ∑ i ∈ [ n ] [ ( x i − x ‾ ) ⋅ ( x i − x ‾ ) T ] ∈ R d × d \Sigma = \frac{1}{n} \sum_{i \in [n]}\left[ (x_i - \overline{x})\cdot (x_i - \overline x)^T \right] \in \mathbb{R}^{d\times d}
Σ = n 1 i ∈ [ n ] ∑ [ ( x i − x ) ⋅ ( x i − x ) T ] ∈ R d × d
严格意义上而言最前面乘上的 1 n \displaystyle \frac{1}{n} n 1 1 n − 1 \displaystyle \frac{1}{n - 1} n − 1 1 1 n \displaystyle \frac{1}{n} n 1 Σ \Sigma Σ
为了求出主成分,我们需要一个单位向量 u 1 ∈ R d u_1 \in \mathbb{R}^d u 1 ∈ R d x i x_i x i x i T u 1 ∈ R x_i^T u_1 \in \mathbb{R} x i T u 1 ∈ R
首先,投影出来的结果的均值为
1 n ∑ i ∈ [ n ] u 1 T x i = 1 n u 1 T ∑ i ∈ [ n ] x i = u 1 T x ‾ \frac{1}{n} \sum_{i \in [n]}u_1^T x_i = \frac{1}{n} u_1^T \sum_{i \in [n]}x_i = u_1^T \overline{x}
n 1 i ∈ [ n ] ∑ u 1 T x i = n 1 u 1 T i ∈ [ n ] ∑ x i = u 1 T x
所以,方差为
1 n ∑ i ∈ [ n ] ( u 1 T x i − u 1 T x ‾ ) 2 = 1 n ∑ i ∈ [ n ] u 1 T ( x i − x ‾ ) ( x i − x ‾ ) T u 1 = u 1 T Σ u 1 \begin{aligned}
\frac{1}{n} \sum_{i \in [n]}(u_1^T x_i - u_1^T \overline{x})^{2} &= \frac{1}{n} \sum_{i \in [n]} u_1^T (x_i - \overline x)(x_i - \overline x)^T u_1 \\
&= u_1^T \Sigma u_1
\end{aligned}
n 1 i ∈ [ n ] ∑ ( u 1 T x i − u 1 T x ) 2 = n 1 i ∈ [ n ] ∑ u 1 T ( x i − x ) ( x i − x ) T u 1 = u 1 T Σ u 1
将这个问题写成带约束(约束来源于单位向量)的优化形式
max u 1 u 1 T Σ u 1 s. t. u 1 T u 1 = 1 \max_{u_1} u_1^T \Sigma u_1\\
\text{s. t. }u_1^T u_1 = 1
u 1 max u 1 T Σ u 1 s. t. u 1 T u 1 = 1
得到拉格朗日函数
L ( u 1 , λ ) = u 1 T Σ u 1 + λ ( 1 − u 1 T u 1 ) \mathcal{L}(u_1, \lambda) = u_1^T \Sigma u_1 + \lambda(1 - u_1^T u_1)
L ( u 1 , λ ) = u 1 T Σ u 1 + λ ( 1 − u 1 T u 1 )
求导:
∂ L ∂ u 1 = 2 Σ u 1 − 2 λ u 1 = 0 ⟹ Σ u 1 = λ u 1 \frac{\partial \mathcal{L}}{\partial u_1} = 2\Sigma u_1 - 2\lambda u_1 = 0\\
\implies \Sigma u_1 = \lambda u_1
∂ u 1 ∂ L = 2 Σ u 1 − 2 λ u 1 = 0 ⟹ Σ u 1 = λ u 1
所以 λ \lambda λ Σ \Sigma Σ 特征值 ,u 1 u_1 u 1 Σ \Sigma Σ 特征向量 。而我们注意到这个方差就是
u 1 T Σ u 1 = u 1 T λ u 1 = λ u_1^T \Sigma u_1 = u_1^T \lambda u_1 = \lambda
u 1 T Σ u 1 = u 1 T λ u 1 = λ
要最大化这个 λ \lambda λ u 1 u_1 u 1 Σ \Sigma Σ 最大的特征值对应的特征向量 。通过这个过程我们可以看出来 Σ \Sigma Σ
接下来考虑求出第二个主成分 u 2 u_2 u 2 u 2 u_2 u 2 u 1 u_1 u 1
max u 2 u 2 T Σ u 2 s. t. u 2 T u 2 = 1 , u 2 T u 1 = 0 \max_{u_2} u_2^T \Sigma u_2\\
\text{s. t. } u_2^Tu_2 = 1, u_2^T u_1 = 0
u 2 max u 2 T Σ u 2 s. t. u 2 T u 2 = 1 , u 2 T u 1 = 0
写出拉格朗日函数并求导:
L ( u 2 , λ 2 , α ) = u 2 T Σ u 2 + λ 2 ( 1 − u 2 T u 2 ) + α u 2 T u 1 ∂ L ∂ u 2 = 2 Σ u 2 − 2 λ 2 u 2 + α u 1 = 0 \begin{aligned}
\mathcal{L}(u_2, \lambda_2, \alpha) &= u_2^T \Sigma u_2 + \lambda_2(1 - u_2^T u_2) + \alpha u_2^T u_1 \\
\frac{\partial \mathcal{L}}{\partial u_2} &= 2 \Sigma u_2 - 2 \lambda_2 u_2 + \alpha u_1 = 0
\end{aligned}
L ( u 2 , λ 2 , α ) ∂ u 2 ∂ L = u 2 T Σ u 2 + λ 2 ( 1 − u 2 T u 2 ) + α u 2 T u 1 = 2 Σ u 2 − 2 λ 2 u 2 + α u 1 = 0
这个时候全部乘一个 u 1 T u_1^T u 1 T
2 u 1 T Σ u 2 − 2 λ 2 u 1 T u 2 + α u 1 T u 1 = 0 \begin{aligned}
2 u_1^T \Sigma u_2 - 2 \lambda_2 u_1^T u_2 + \alpha u_1^T u_1 &= 0 \\
\end{aligned}
2 u 1 T Σ u 2 − 2 λ 2 u 1 T u 2 + α u 1 T u 1 = 0
注意到 u 1 T Σ u 2 = u 2 T Σ u 1 = u 2 T λ u 1 = 0 u_1^T \Sigma u_2 = u_2^T \Sigma u_1 = u_2^T \lambda u_1 = 0 u 1 T Σ u 2 = u 2 T Σ u 1 = u 2 T λ u 1 = 0 α = 0 \alpha = 0 α = 0 Σ u 2 = λ 2 u 2 \Sigma u_2 = \lambda_2 u_2 Σ u 2 = λ 2 u 2 u 2 , λ u_2, \lambda u 2 , λ Σ \Sigma Σ u 2 u_2 u 2 Σ \Sigma Σ
可以归纳得到一个很强的结论:
Eckart- Young Theorem
前 k k k Σ \Sigma Σ k k k
于是我们得到 PCA 算法的通用流程:
计算 Σ \Sigma Σ
做特征值分解 Σ = U Λ U T \Sigma = U \Lambda U^T Σ = U Λ U T
选前 k k k [ u 1 , u 2 , ⋯ , u k ] = U 1 : k ∈ R d × k [u_1, u_2, \cdots , u_k] = U_{1:k} \in \mathbb{R}^{d \times k} [ u 1 , u 2 , ⋯ , u k ] = U 1 : k ∈ R d × k
U 1 : k T x i U_{1:k}^T x_i U 1 : k T x i x i ∈ R d x_i \in \mathbb{R}^d x i ∈ R d R k \mathbb{R}^k R k
实际上,矩阵的特征值(从大到小)会迅速衰减,后面的会变得非常小,所以去掉这些特征维度影响不大。此乃 PCA 分解成功的理论解释。
考虑另一种 PCA 算法。
定义
X ^ = [ x 1 T − x ‾ T ⋮ x n T − x ‾ T ] ∈ R n × d \hat{X} = \begin{bmatrix} x_1^T - \overline x^T \\ \vdots \\ x_n^T - \overline x^T \\\end{bmatrix} \in \mathbb{R}^{n \times d}
X ^ = ⎣ ⎢ ⎢ ⎡ x 1 T − x T ⋮ x n T − x T ⎦ ⎥ ⎥ ⎤ ∈ R n × d
于是 Σ = 1 n X ^ T X ^ \Sigma = \displaystyle \frac{1}{n} \hat{X}^T \hat{X} Σ = n 1 X ^ T X ^
由于我们事实上不关心 Σ \Sigma Σ X ^ T \hat{X}^T X ^ T
X ^ T = U S V T \hat{X}^T = U S V^T
X ^ T = U S V T
其中 U ∈ R d × d , S ∈ R d × n , V ∈ R n × n U \in \mathbb{R}^{d \times d}, S \in \mathbb{R}^{d \times n}, V \in \mathbb{R}^{n \times n} U ∈ R d × d , S ∈ R d × n , V ∈ R n × n U U U V V V
X ^ T X ^ = U S V T V S T U T = U S S T U T = U Λ U T \hat{X}^T \hat{X} = USV^T V S^T U^T = USS^TU^T = U \Lambda U^T
X ^ T X ^ = U S V T V S T U T = U S S T U T = U Λ U T
所以对 X ^ T \hat{X}^T X ^ T Σ \Sigma Σ X ^ T \hat{X}^T X ^ T U U U
考虑两种方法的复杂度:对 Σ \Sigma Σ O ( d 3 ) O(d^3) O ( d 3 ) X ^ T \hat{X}^T X ^ T O ( n d 2 ) O(nd^2) O ( n d 2 ) Σ \Sigma Σ O ( n d 2 ) O(nd^2) O ( n d 2 )
给定 D = { x 1 , ⋯ , x n } , x i ∈ R d D = \{x_1, \cdots ,x_n\}, x_i \in \mathbb{R}^d D = { x 1 , ⋯ , x n } , x i ∈ R d D D D k k k k k k
我们需要找到每个类簇的中心点 μ i , i ∈ [ k ] \mu_i, i \in [k] μ i , i ∈ [ k ]
目标:找到所有的 { μ i ∣ i ∈ [ k ] } \{\mu_i \mid i \in [k]\} { μ i ∣ i ∈ [ k ] } x i x_i x i
定义
r i j = { 1 , x i is assigned to cluster j 0 , otherwise r_{ij} = \begin{cases} 1, & x_i \text{ is assigned to cluster }j \\ 0, & \text{otherwise} \end{cases}
r i j = { 1 , 0 , x i is assigned to cluster j otherwise
注意其需满足性质 ∀ i , ∑ j ∈ [ k ] r i j = 1 \forall i, \displaystyle \sum_{j \in [k]} r_{ij} = 1 ∀ i , j ∈ [ k ] ∑ r i j = 1
那么 k-means 的目标就可以写成
L : = min r , μ ∑ i ∈ [ n ] ∑ j ∈ [ k ] r i j ∥ x i − μ j ∥ 2 L := \min_{r,\mu} \sum_{i \in [n]} \sum_{j \in [k]} r_{ij} \left\| x_i - \mu_j \right\|^{2}
L : = r , μ min i ∈ [ n ] ∑ j ∈ [ k ] ∑ r i j ∥ x i − μ j ∥ 2
但是 r i j r_{ij} r i j
不过还是可以做的,迭代地重复如下两个步骤:
固定 μ \mu μ r r r
r i j = { 1 , k = arg min j ∈ [ k ] ∥ x i − x j ∥ 2 0 , otherwise r_{ij} = \begin{cases} 1, & k = \arg\min_{j \in [k]} \left\| x_i - x_j \right\|^{2} \\ 0, & \text{otherwise} \end{cases}
r i j = { 1 , 0 , k = arg min j ∈ [ k ] ∥ x i − x j ∥ 2 otherwise
即根据当前 已经确定好的类簇中心来重新分配每个点。
固定 r r r μ \mu μ
∂ L ∂ μ j = − ∑ i ∈ [ n ] r i j ⋅ 2 ( x i − μ j ) = 0 μ j = ∑ i ∈ [ n ] r i j ⋅ x i ∑ i ∈ [ n ] r i j \begin{aligned}
\frac{\partial L}{\partial \mu_j} &= -\sum_{i \in [n]}r_{ij} \cdot 2 (x_i - \mu_j) = 0 \\
\mu_j &= \frac{\sum_{i \in [n]}r_{ij} \cdot x_i}{\sum_{i \in [n]}r_{ij}}
\end{aligned} ∂ μ j ∂ L μ j = − i ∈ [ n ] ∑ r i j ⋅ 2 ( x i − μ j ) = 0 = ∑ i ∈ [ n ] r i j ∑ i ∈ [ n ] r i j ⋅ x i
此时 μ j \mu_j μ j 当前 的 r r r j j j
反复迭代直到收敛(r r r μ \mu μ
不过 k-means 找到的解未必是全局最优解。因为这个迭代流程可以理解为在 μ \mu μ r r r
在 k-means 中,我们用的是 hard assignment。而在 MoG 中,我们将类簇 j j j N ( μ j , Σ j ) \mathcal{N}(\mu_j, \Sigma_j) N ( μ j , Σ j ) π j \pi_j π j ∑ π j = 1 \sum \pi_j = 1 ∑ π j = 1
对于一个随机变量 x x x z j z_j z j 隐变量 ,取值为 { 0 , 1 } \{0,1\} { 0 , 1 } z j = 1 z_j = 1 z j = 1 x x x j j j ∑ z j = 1 \sum z_j = 1 ∑ z j = 1 x x x
MoG 同时也可以是生成模型,可以生成与训练数据分布相似的数据。
于是显然 P ( x ∣ z j = 1 ) = N ( x ∣ μ j , Σ j ) P(x\mid z_j = 1) = \mathcal{N}(x\mid \mu_j, \Sigma_j) P ( x ∣ z j = 1 ) = N ( x ∣ μ j , Σ j ) μ j \mu_j μ j Σ j \Sigma_j Σ j μ j \mu_j μ j j j j
但是,我们在训练数据中是不知道每个点是属于哪个类簇的,所以像 P ( x ∣ z j = 1 ) P(x\mid z_j=1) P ( x ∣ z j = 1 ) P ( x ) P(x) P ( x )
P ( x ) = ∑ z P ( x , z ) marginalization = ∑ z P ( x ∣ z ) P ( z ) note that z can be easily enumerated = ∑ j ∈ [ k ] π j ⋅ N ( x ∣ μ j , Σ j ) \begin{aligned}
P(x) &= \sum_{z} P(x,z) & \text{marginalization} \\
&= \sum_z P(x\mid z) P(z) & \text{note that }z\text{ can be easily enumerated}\\
&= \sum_{j \in [k]} \pi_j \cdot \mathcal{N}(x\mid \mu_j, \Sigma_j)
\end{aligned}
P ( x ) = z ∑ P ( x , z ) = z ∑ P ( x ∣ z ) P ( z ) = j ∈ [ k ] ∑ π j ⋅ N ( x ∣ μ j , Σ j ) marginalization note that z can be easily enumerated
注意到 z z z one-hot 编码 ,所以实际上只有 k k k z z z
对这个东西就可以考虑使用 MLE 来优化其对数似然了:
max π , μ , Σ ∑ i ∈ [ n ] log ( ∑ j ∈ [ k ] π j ⋅ N ( x i ∣ μ j , Σ j ) ) s. t. ∑ j ∈ [ k ] π j = 1 , ∀ j , Σ j ⪰ 0 \max_{\pi,\mu,\Sigma} \sum_{i \in [n]} \log\left( \sum_{j \in [k]}\pi_j \cdot \mathcal{N}(x_i\mid \mu_j, \Sigma_j) \right)\\
\text{s. t. }\sum_{j \in [k]}\pi_j = 1, \forall j,\Sigma_j \succeq 0
π , μ , Σ max i ∈ [ n ] ∑ log ⎝ ⎛ j ∈ [ k ] ∑ π j ⋅ N ( x i ∣ μ j , Σ j ) ⎠ ⎞ s. t. j ∈ [ k ] ∑ π j = 1 , ∀ j , Σ j ⪰ 0
如果想用梯度下降的话就需要处理这两个额外的限制条件。前者关于 π \pi π
先考虑一般情况下的 EM,推导完毕后再带回 MoG。
假设 θ \theta θ { x 1 , ⋯ , x n } \{x_1, \cdots ,x_n\} { x 1 , ⋯ , x n } P ( x ; θ ) P(x;\theta) P ( x ; θ ) P ( x i , θ ) P(x_i,\theta) P ( x i , θ ) P ( x i ; θ ) = ∑ z j P ( x i , z j ; θ ) P(x_i;\theta) = \displaystyle \sum_{z_j} P(x_i,z_j;\theta) P ( x i ; θ ) = z j ∑ P ( x i , z j ; θ ) P ( x ; θ ) P(x;\theta) P ( x ; θ ) P ( x , z ; θ ) P(x,z;\theta) P ( x , z ; θ )
我们引入一个 P ( z ∣ x ; θ ) P(z\mid x;\theta) P ( z ∣ x ; θ ) q ( z ∣ x ) q(z\mid x) q ( z ∣ x )
引入一个简单易求的分布 q q q P P P
log P ( x ; θ ) = ∑ z q ( z ∣ x ) ⋅ log P ( x ; θ ) = ∑ z q ( z ∣ x ) ⋅ [ log P ( x , z ; θ ) − log P ( z ∣ x ; θ ) ] = ∑ z q ( z ∣ x ) ⋅ [ log P ( x , z ; θ ) − log q ( z ∣ x ) − log P ( z ∣ x ; θ ) + log q ( z ∣ x ) ] = ∑ z q ( z ∣ x ) log P ( x , z ; θ ) q ( z ∣ x ) − ∑ z q ( z ∣ x ) log P ( z ∣ x , θ ) q ( z ∣ x ) = L ( q , θ ) + K L ( q ∥ p ) \begin{aligned}
\log P(x;\theta) &= \sum_z q(z\mid x) \cdot \log P(x;\theta) \\
&= \sum_z q(z\mid x) \cdot \left[ \log P(x,z;\theta) - \log P(z\mid x; \theta) \right]\\
&= \sum_z q(z\mid x) \cdot \left[ \log P(x,z;\theta) {\color{red}{ - \log q(z\mid x)}} - \log P(z\mid x; \theta) {\color{red}{+ \log q(z\mid x)}} \right]\\
&= \sum_z q(z\mid x) \log \frac{P(x,z; \theta)}{q(z\mid x)} - \sum_z q(z\mid x) \log \frac{P(z\mid x, \theta)}{q(z\mid x)}\\
&= L(q, \theta) + \mathrm{KL}(q\parallel p)
\end{aligned}
log P ( x ; θ ) = z ∑ q ( z ∣ x ) ⋅ log P ( x ; θ ) = z ∑ q ( z ∣ x ) ⋅ [ log P ( x , z ; θ ) − log P ( z ∣ x ; θ ) ] = z ∑ q ( z ∣ x ) ⋅ [ log P ( x , z ; θ ) − l o g q ( z ∣ x ) − log P ( z ∣ x ; θ ) + l o g q ( z ∣ x ) ] = z ∑ q ( z ∣ x ) log q ( z ∣ x ) P ( x , z ; θ ) − z ∑ q ( z ∣ x ) log q ( z ∣ x ) P ( z ∣ x , θ ) = L ( q , θ ) + K L ( q ∥ p )
解释:第一行是利用 ∑ z q ( z ∣ x ) = 1 \displaystyle \sum_z q(z\mid x) = 1 z ∑ q ( z ∣ x ) = 1 P ( x , z ) = P ( x ) P ( z ∣ x ) P(x,z) = P(x)P(z\mid x) P ( x , z ) = P ( x ) P ( z ∣ x )
先分析右边的 KL 散度(Kullback-Leibler Divergence):其度量两个分布之间的差异。
K L ( p ∥ q ) = − ∑ z q ( z ∣ x ) log P ( z ∣ x ; θ ) − [ − ∑ z q ( z ∣ x ) log q ( z ∣ x ) ] \mathrm{KL}(p\parallel q) = - \sum_z q(z\mid x) \log P(z\mid x; \theta) - \left[ - \sum_z q(z\mid x) \log q(z\mid x) \right]
K L ( p ∥ q ) = − z ∑ q ( z ∣ x ) log P ( z ∣ x ; θ ) − [ − z ∑ q ( z ∣ x ) log q ( z ∣ x ) ]
后者就是 q ( z ∣ x ) q(z\mid x) q ( z ∣ x ) p p p q q q
根据 log \log log
∑ z q ( z ∣ x ) log P ( z ∣ x ; θ ) q ( z ∣ x ) ≤ log ∑ z q ( z ∣ x ) P ( z ∣ x ; θ ) q ( z ∣ x ) = 0 \sum_z q(z\mid x) \log \frac{P(z\mid x;\theta)}{q(z\mid x)} \le \log \sum_z q(z\mid x) \frac{P(z\mid x; \theta)}{q(z\mid x)} = 0
z ∑ q ( z ∣ x ) log q ( z ∣ x ) P ( z ∣ x ; θ ) ≤ log z ∑ q ( z ∣ x ) q ( z ∣ x ) P ( z ∣ x ; θ ) = 0
所以得到 KL 散度非常重要的两个性质:
K L ( q ∥ p ) ≥ 0 \mathrm{KL}(q\parallel p) \ge 0 K L ( q ∥ p ) ≥ 0 等于 0 0 0 p = q p = q p = q
交叉熵与 KL 散度之间的联系:
对于监督学习 (如逻辑回归),优化交叉熵和 KL 散度是没有区别的。因为 q q q p p p
同时,他们两个都是不对称的。K L ( p ∥ q ) ≠ K L ( q ∥ p ) \mathrm{KL}(p\parallel q) \neq \mathrm{KL}(q\parallel p) K L ( p ∥ q ) = K L ( q ∥ p ) H ( p , q ) ≠ H ( q , p ) H(p,q) \neq H(q,p) H ( p , q ) = H ( q , p )
接下来看前面的 L ( q ; θ ) L(q;\theta) L ( q ; θ ) q q q 泛函 (函数的函数,functional)。因为 K L ( q ∥ p ) ≥ 0 \mathrm{KL}(q\parallel p)\ge 0 K L ( q ∥ p ) ≥ 0 L ( q ; θ ) = log P ( x ; θ ) − K L ( q ∥ p ) ≤ log P ( x ; θ ) L(q;\theta) = \log P(x;\theta) - \mathrm{KL}(q\parallel p) \le \log P(x; \theta) L ( q ; θ ) = log P ( x ; θ ) − K L ( q ∥ p ) ≤ log P ( x ; θ ) L ( q ; θ ) L(q;\theta) L ( q ; θ ) P ( x ; θ ) P(x;\theta) P ( x ; θ ) 下界 ,称为置信下界 Evidence Lower Bound (ELBO) 。
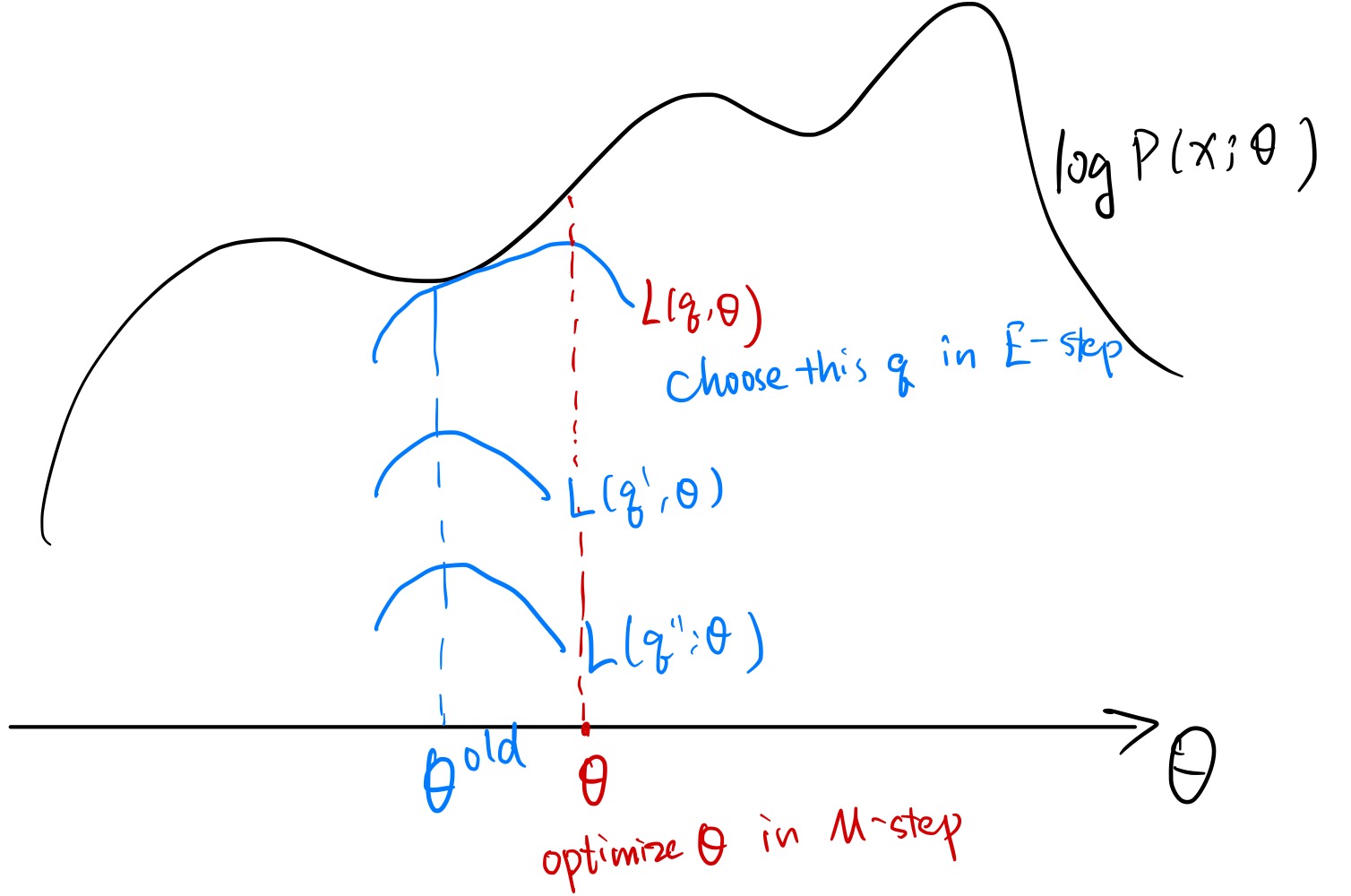
完成上述推导后正式引入 EM 算法:一种用于优化 ELBO 的两步的迭代算法。注意到这个泛函有 q , θ q,\theta q , θ
E-step (expectation) :给定 θ \theta θ q q q θ = θ old \theta = \theta^{\text{old}} θ = θ old L ( q , θ old ) L(q,\theta^{\text{old}}) L ( q , θ old ) q q q θ \theta θ log P ( x ; θ ) \log P(x;\theta) log P ( x ; θ ) L ( q ; θ ) = log P ( x ; θ ) − K L ( q ∥ p ) L(q;\theta) = \log P(x;\theta) - KL(q\parallel p) L ( q ; θ ) = log P ( x ; θ ) − K L ( q ∥ p ) K L ( q ∥ p ) KL(q\parallel p) K L ( q ∥ p ) q ← p q \gets p q ← p q ( z ∣ x ) = P ( z ∣ x ; θ old ) q(z\mid x) = P(z\mid x; \theta^{\text{old}}) q ( z ∣ x ) = P ( z ∣ x ; θ old )
M-step (maximization) :给定 q q q θ \theta θ q ( z ∣ x ) = P ( z ∣ x ; θ old ) q(z\mid x) = P(z\mid x; \theta^{\text{old}}) q ( z ∣ x ) = P ( z ∣ x ; θ old ) L ( q ; θ ) L(q;\theta) L ( q ; θ )
L ( q ; θ ) = ∑ z P ( z ∣ x ; θ old ) log P ( x , z ; θ ) P ( z ∣ x ; θ o l d ) = ∑ z P ( z ∣ x ; θ old ) log P ( x , z ; θ ) − ∑ z P ( z ∣ x ; θ old ) log ( z ∣ x ; θ old ) \begin{aligned}
L(q;\theta) &= \sum_z P(z\mid x; \theta^{\text{old}}) \log \frac{P(x,z;\theta)}{P(z\mid x; \theta^{old})} \\
&= \sum_z P(z\mid x; \theta^{\text{old}}) \log P(x,z;\theta) - \sum_z P(z\mid x; \theta^{\text{old}}) \log(z\mid x; \theta^{\text{old}})\\
\end{aligned}
L ( q ; θ ) = z ∑ P ( z ∣ x ; θ old ) log P ( z ∣ x ; θ o l d ) P ( x , z ; θ ) = z ∑ P ( z ∣ x ; θ old ) log P ( x , z ; θ ) − z ∑ P ( z ∣ x ; θ old ) log ( z ∣ x ; θ old )
后者是常数,与 θ \theta θ
max θ ∑ z P ( z ∣ x ; θ old ) log P ( x , z ; θ ) \max_\theta \sum_z P(z\mid x; \theta^{\text{old}}) \log P(x,z;\theta)
θ max z ∑ P ( z ∣ x ; θ old ) log P ( x , z ; θ )
即等价于优化期望
E z ∼ P ( z ∣ x , θ old ) [ log P ( x , z ; θ ) ] \mathbb{E}_{z \sim P(z\mid x, \theta^{\text{old}})}\left[ \log P(x,z;\theta) \right]
E z ∼ P ( z ∣ x , θ old ) [ log P ( x , z ; θ ) ]
重复 E-step 和 M-step 直到收敛,示意图如下:
MoG 我们要优化的对数似然为
log P ( X ; θ ) = ∑ i ∈ [ n ] log ∑ j ∈ [ K ] π j N ( x i ∣ μ j , Σ j ) \log P(X;\theta) = \sum_{i \in [n]} \log \sum_{j \in [K]} \pi_j \mathcal{N}(x_i\mid \mu_j, \Sigma_j)
log P ( X ; θ ) = i ∈ [ n ] ∑ log j ∈ [ K ] ∑ π j N ( x i ∣ μ j , Σ j )
E-step :拿真实数据在当前参数下的后验来替代变分分布 q q q
q ( Z ∣ X ) = P ( Z ∣ X ; μ old , Σ old , π old ) = ∏ i ∈ [ n ] P ( z i ∣ x i ; μ old , Σ old , π old ) \begin{aligned}
q(Z\mid X) &= P(Z\mid X; \mu^{\text{old}}, \Sigma^{\text{old}}, \pi^{\text{old}}) \\
&= \prod_{i \in [n]} P(z_i\mid x_i; \mu^{\text{old}}, \Sigma^{\text{old}}, \pi^{\text{old}})
\end{aligned}
q ( Z ∣ X ) = P ( Z ∣ X ; μ old , Σ old , π old ) = i ∈ [ n ] ∏ P ( z i ∣ x i ; μ old , Σ old , π old )
第一行到第二行是基于数据点间分布是独立的。接下来推导
P ( z i ∣ x i ; μ old , Σ old , π old ) = P ( x i , z i ) P ( x i ) = P ( x i ∣ z i ) P ( z i ) P ( x i ) = ∏ j ∈ [ K ] [ π j N ( x i ∣ μ j , Σ j ) ] z i j ∑ j ∈ [ K ] π j N ( x i ∣ μ j , Σ j ) \begin{aligned}
P(z_i\mid x_i; \mu^{\text{old}}, \Sigma^{\text{old}}, \pi^{\text{old}}) &= \frac{P(x_i,z_i)}{P(x_i)} \\
&= \frac{P(x_i\mid z_i) P(z_i)}{P(x_i)}\\
&= \frac{\prod_{j \in [K]}\left[ \pi_j \mathcal{N}(x_i\mid \mu_j, \Sigma_j) \right]^{z_{ij}} }{\sum_{j \in [K]} \pi_j \mathcal{N}(x_i\mid \mu_j, \Sigma_j)}
\end{aligned}
P ( z i ∣ x i ; μ old , Σ old , π old ) = P ( x i ) P ( x i , z i ) = P ( x i ) P ( x i ∣ z i ) P ( z i ) = ∑ j ∈ [ K ] π j N ( x i ∣ μ j , Σ j ) ∏ j ∈ [ K ] [ π j N ( x i ∣ μ j , Σ j ) ] z i j
第三行分子上是一个 index trick。
M-step :优化 E z ∼ q ( Z ∣ X ) [ log P ( X , Z ∣ μ , Σ , π ) ] \displaystyle \mathbb{E}_{z \sim q(Z\mid X)}[\log P(X,Z\mid \mu, \Sigma, \pi)] E z ∼ q ( Z ∣ X ) [ log P ( X , Z ∣ μ , Σ , π ) ]
P ( X , Z ) = ∏ i ∈ [ n ] P ( x i ∣ z i ) P ( z i ) = ∏ i ∈ [ n ] ∏ j ∈ [ K ] [ π j N ( x i ∣ μ j , Σ j ) ] z i j \begin{aligned}
P(X,Z) &= \prod_{i \in [n]} P(x_i\mid z_i) P(z_i) \\
&= \prod_{i \in [n]}\prod_{j \in [K]}\left[ \pi_j \mathcal{N}(x_i\mid \mu_j, \Sigma_j) \right]^{z_{ij}}
\end{aligned}
P ( X , Z ) = i ∈ [ n ] ∏ P ( x i ∣ z i ) P ( z i ) = i ∈ [ n ] ∏ j ∈ [ K ] ∏ [ π j N ( x i ∣ μ j , Σ j ) ] z i j
要优化的是其期望:
E z ∼ q ( Z ∣ X ) [ log P ( X , Z ∣ μ , Σ , π ) ] = E z [ ∑ i ∈ [ n ] ∑ j ∈ [ K ] z i j log π j N ( x i ∣ μ j , Σ j ) ] = ∑ i ∈ [ n ] ∑ j ∈ [ K ] E z [ z i j ] log π j N ( x i ∣ μ j , Σ j ) \begin{aligned}
&\mathbb{E}_{z \sim q(Z\mid X)}[\log P(X,Z\mid \mu, \Sigma, \pi)] \\
=& \mathbb{E}_z \left[ \sum_{i \in [n]} \sum_{j \in [K]} z_{ij} {\color{red}{\log \pi_j \mathcal{N}(x_i\mid \mu_j,\Sigma_j)}} \right]\\
=& \sum_{i \in [n]} \sum_{j \in [K]} \mathbb{E}_z[z_{ij}]\log \pi_j \mathcal{N}(x_i\mid \mu_j,\Sigma_j)
\end{aligned}
= = E z ∼ q ( Z ∣ X ) [ log P ( X , Z ∣ μ , Σ , π ) ] E z ⎣ ⎢ ⎡ i ∈ [ n ] ∑ j ∈ [ K ] ∑ z i j l o g π j N ( x i ∣ μ j , Σ j ) ⎦ ⎥ ⎤ i ∈ [ n ] ∑ j ∈ [ K ] ∑ E z [ z i j ] log π j N ( x i ∣ μ j , Σ j )
(上式中红色部分与 z z z E z [ z i j ] \mathbb{E}_z[z_{ij}] E z [ z i j ]
E z [ z i j ] = P ( z i j = 1 ∣ x i ; θ old ) ⋅ 1 + P ( z i j = 0 ∣ x i ; θ old ) ⋅ 0 = P ( z i j = 1 ∣ x i ; θ old ) = π j N ( x i ∣ μ j , Σ j ) ∑ t ∈ [ K ] π t N ( x i ∣ μ t , Σ t ) : = γ i j \begin{aligned}
\mathbb{E}_z[z_{ij}] &= P(z_{ij}=1\mid x_i; \theta^{\text{old}}) \cdot 1 + P(z_{ij}=0\mid x_i;\theta^{\text{old}})\cdot 0 \\
&= P(z_{ij}=1\mid x_i; \theta^{\text{old}})\\
&= \frac{\pi_j \mathcal{N}(x_i\mid \mu_j,\Sigma_j)}{\sum_{t \in [K]} \pi_t \mathcal{N}(x_i\mid \mu_t, \Sigma_t)} := \gamma_{ij}
\end{aligned}
E z [ z i j ] = P ( z i j = 1 ∣ x i ; θ old ) ⋅ 1 + P ( z i j = 0 ∣ x i ; θ old ) ⋅ 0 = P ( z i j = 1 ∣ x i ; θ old ) = ∑ t ∈ [ K ] π t N ( x i ∣ μ t , Σ t ) π j N ( x i ∣ μ j , Σ j ) : = γ i j
最后一行是因为,在这个式子里所有的参数都是旧参数,所以可以算出来一个常数 γ i j \gamma_{ij} γ i j j j j x i x_i x i r i j r_{ij} r i j
∑ j ∈ [ K ] γ i j = 1 \sum_{j \in [K]} \gamma_{ij} = 1
j ∈ [ K ] ∑ γ i j = 1
现在可以重写我们需要优化的东西了:
max μ , Σ , π ∑ i ∈ [ n ] ∑ j ∈ [ K ] γ i j log π j N ( x i ∣ μ k , Σ k ) s. t. ∑ j ∈ [ K ] π j = 1 \max_{\mu,\Sigma, \pi} \sum_{i \in [n]}\sum_{j \in [K]} \gamma_{ij} \log \pi_j \mathcal{N}(x_i\mid \mu_k, \Sigma_k)\\
\text{s. t. }\sum_{j \in [K]}\pi_j = 1
μ , Σ , π max i ∈ [ n ] ∑ j ∈ [ K ] ∑ γ i j log π j N ( x i ∣ μ k , Σ k ) s. t. j ∈ [ K ] ∑ π j = 1
将这个限制写在拉格朗日函数中:
L ( μ , Σ , π , λ ) = ∑ i ∈ [ n ] ∑ j ∈ [ K ] γ i j log π j N ( x i ∣ μ k , Σ k ) + λ ( 1 − ∑ j ∈ [ K ] π j ) \mathcal{L}(\mu,\Sigma,\pi,\lambda) = \sum_{i \in [n]}\sum_{j \in [K]} \gamma_{ij} \log \pi_j \mathcal{N}(x_i\mid \mu_k, \Sigma_k) + \lambda\left( 1 - \sum_{j \in [K]}\pi_j \right)
L ( μ , Σ , π , λ ) = i ∈ [ n ] ∑ j ∈ [ K ] ∑ γ i j log π j N ( x i ∣ μ k , Σ k ) + λ ⎝ ⎛ 1 − j ∈ [ K ] ∑ π j ⎠ ⎞
对于 π \pi π
∂ L ∂ π j = 0 ⟹ ∑ i ∈ [ n ] γ i j N ( x i ∣ μ k , Σ k ) π j N ( x i ∣ μ k , Σ k ) − λ = 0 ⟹ π j λ = ∑ i ∈ [ n ] γ i j ⟹ λ ∑ j ∈ [ K ] π j = ∑ i ∈ [ n ] ∑ j ∈ [ K ] γ i j ⟹ λ = n ⟹ π j = 1 n ∑ i ∈ [ n ] γ i j \begin{aligned}
\displaystyle \frac{\partial \mathcal{L}}{\partial \pi_j} = 0 &\implies \sum_{i \in [n]} \gamma_{ij} \frac{\mathcal{N}(x_i\mid \mu_k, \Sigma_k)}{\pi_j\mathcal{N}(x_i\mid \mu_k, \Sigma_k)} - \lambda = 0\\
&\implies \pi_j \lambda = \sum_{i \in [n]} \gamma_{ij}\\
&\implies \lambda \sum_{j \in [K]}\pi_j = \sum_{i \in [n]}\sum_{j \in [K]}\gamma_{ij}\\
&\implies \lambda = n\\
&\implies \pi_j = \frac{1}{n}\sum_{i \in [n]}\gamma_{ij}
\end{aligned}
∂ π j ∂ L = 0 ⟹ i ∈ [ n ] ∑ γ i j π j N ( x i ∣ μ k , Σ k ) N ( x i ∣ μ k , Σ k ) − λ = 0 ⟹ π j λ = i ∈ [ n ] ∑ γ i j ⟹ λ j ∈ [ K ] ∑ π j = i ∈ [ n ] ∑ j ∈ [ K ] ∑ γ i j ⟹ λ = n ⟹ π j = n 1 i ∈ [ n ] ∑ γ i j
第三行是左右对 j j j λ \lambda λ π j \pi_j π j j j j
对于 μ \mu μ N ( x i ∣ μ j , Σ j \mathcal{N}(x_i\mid \mu_j,\Sigma_j N ( x i ∣ μ j , Σ j
N ( x i ∣ μ j , Σ j ) = 1 ( 2 π ) d 2 ( det Σ j ) 1 2 exp ( − 1 2 ( x i − μ j ) T Σ j − 1 ( x i − μ j ) ) \mathcal{N}(x_i\mid \mu_j, \Sigma_j) = \frac{1}{(2\pi)^{\frac{d}{2}} (\det\Sigma_j)^{\frac{1}{2}}} \exp\left( -\frac{1}{2}(x_i - \mu_j)^T \Sigma_j^{-1}(x_i - \mu_j) \right)
N ( x i ∣ μ j , Σ j ) = ( 2 π ) 2 d ( det Σ j ) 2 1 1 exp ( − 2 1 ( x i − μ j ) T Σ j − 1 ( x i − μ j ) )
然后化简一下原式
∑ i ∈ [ n ] ∑ j ∈ [ K ] γ i j [ log π j − d 2 log ( 2 π ) − 1 2 log det Σ j − 1 2 ( x i − μ j ) T Σ j − 1 ( x i − μ j ) ] \sum_{i \in [n]} \sum_{j \in [K]} \gamma_{ij}\left[ \log \pi_j - \frac{d}{2}\log(2\pi) - \frac{1}{2} \log \det \Sigma_j - \frac{1}{2}(x_i - \mu_j)^T \Sigma_j^{-1}(x_i - \mu_j) \right]
i ∈ [ n ] ∑ j ∈ [ K ] ∑ γ i j [ log π j − 2 d log ( 2 π ) − 2 1 log det Σ j − 2 1 ( x i − μ j ) T Σ j − 1 ( x i − μ j ) ]
接下来令
∂ L ∂ μ j = 0 ⟹ ∑ i ∈ [ n ] γ i j Σ j − 1 ( x i − μ j ) = 0 ⟹ ∑ i ∈ [ n ] γ i j x i = ∑ i ∈ [ n ] γ i j μ j ⟹ μ j = ∑ i ∈ [ n ] γ i j x i ∑ i ∈ [ n ] γ i j \begin{aligned}
\frac{\partial \mathcal{L}}{\partial \mu_j} = 0 &\implies \sum_{i \in [n]} \gamma_{ij} \Sigma_j^{-1}(x_i - \mu_j) = 0 \\
&\implies \sum_{i \in [n]}\gamma_{ij} x_i = \sum_{i \in [n]}\gamma_{ij}\mu_j\\
&\implies \mu_j = \frac{\sum_{i \in [n]}\gamma_{ij}x_i}{\sum_{i \in [n]}\gamma_{ij}}
\end{aligned}
∂ μ j ∂ L = 0 ⟹ i ∈ [ n ] ∑ γ i j Σ j − 1 ( x i − μ j ) = 0 ⟹ i ∈ [ n ] ∑ γ i j x i = i ∈ [ n ] ∑ γ i j μ j ⟹ μ j = ∑ i ∈ [ n ] γ i j ∑ i ∈ [ n ] γ i j x i
这个结果也挺符合物理直觉的。相当于对所有的 x i x_i x i j j j
最后考虑 Σ \Sigma Σ Σ \Sigma Σ Σ − 1 \Sigma^{-1} Σ − 1
∂ L ∂ Σ j − 1 = 0 ⟹ ∑ i ∈ [ n ] γ i j 1 det Σ j ∂ det Σ j ∂ Σ j − 1 + γ i j ( x i − μ j ) ( x i − μ j ) T = 0 ⟹ Σ j = ∑ i ∈ [ n ] γ i j ( x i − μ j ) ( x i − μ j ) T ∑ i ∈ [ n ] γ i j \begin{aligned}
\frac{\partial \mathcal{L}}{\partial \Sigma_j^{-1}} = 0 &\implies \sum_{i \in [n]}\gamma_{ij} \frac{1}{\det \Sigma_j} \frac{\partial \det\Sigma_j}{\partial \Sigma_j^{-1}} + \gamma_{ij}(x_i - \mu_j)(x_i - \mu_j)^T = 0 \\
&\implies \Sigma_j = \frac{\sum_{i \in [n]}\gamma_{ij}(x_i - \mu_j)(x_i - \mu_j)^T}{\sum_{i \in [n]}\gamma_{ij}}
\end{aligned}
∂ Σ j − 1 ∂ L = 0 ⟹ i ∈ [ n ] ∑ γ i j det Σ j 1 ∂ Σ j − 1 ∂ det Σ j + γ i j ( x i − μ j ) ( x i − μ j ) T = 0 ⟹ Σ j = ∑ i ∈ [ n ] γ i j ∑ i ∈ [ n ] γ i j ( x i − μ j ) ( x i − μ j ) T
用到的公式:
∂ a T x b ∂ x = a b T ∂ det x − 1 ∂ x = − det x − 1 ⋅ ( x − 1 ) T \frac{\partial a^Txb}{\partial x} = ab^T\\
\frac{\partial \det x^{-1}}{\partial x}=- \det x^{-1} \cdot (x^{-1})^T
∂ x ∂ a T x b = a b T ∂ x ∂ det x − 1 = − det x − 1 ⋅ ( x − 1 ) T
也有符合直觉的意义:empirical estimation of covariance weighted by γ i j \gamma_{ij} γ i j
MoG 与 k-means 之间的联系:当 Σ j = σ 2 I \Sigma_j = \sigma^2 I Σ j = σ 2 I σ → 0 \sigma \to 0 σ → 0