Last updated on December 20, 2025 9:30 PM
本文主要涉及支持向量机(Support Vector Machine)以及对偶理论。
一键回城。
本文所涉及部分用了 3 个课时来讲述,内容较多。
带约束的优化问题
先介绍一般性的优化问题,进而引出 K.K.T 条件。
等式约束下的优化问题
minxf(x),s. t. h(x)=0,其中 f,h 都可微。
- ∀x 在平面 h(x)=0 上,有 ∇h(x) 与平面正交。
如果有切向分量,说明我们沿着切向走可以使得 h(x)>0,与 h(x)=0 矛盾。
- 对于一个局部最小值 x∗,梯度 ∇f(x∗) 也与平面垂直。
若有切向分量,则沿着其反方向走,可以保证 h(x)=0 的约束不变,且 f 可以继续降低。
一般而言,x∗ 为局部最小值的必要条件为:∃λ 使得 ∇f(x∗)+λ∇h(x∗)=0,即这两个梯度共线;以及 h(x∗)=0。
不考虑 corner cases(事实上在实际中也少见):我们需要 x∗ 为 regular point。
引入拉格朗日方程
L(x,λ)=f(x)+λh(x)
其中 λ 为拉格朗日乘子。
如果有多个约束,则
L(x,[λ1,⋯,λn])=f(x)+i∈[n]∑λihi(x)
此时,x∗ 为局部最小值的必要条件可以写为:∃λ 使得
{∇xL(x∗,λ)=0∇λL(x∗,λ)=0
第一个式子等价于 ∇f(x∗)+λ∇h(x∗)=0,第二个等价于 h(x∗)=0。
无限制优化的时候,我们其实只需要 ∇f(x∗)=0,加上了约束之后,我们就利用拉格朗日乘子把约束放进方程里面。
同时,需要留意的是,如上为必要条件而非充分条件。
- 从拉格朗日条件解出来的解可能不是局部最小解
- 但是,所有的局部最小解肯定在我们解出来的 candidate set 里面。
- 对于凸函数,局部最小解即为全局最小解。
带不等式约束的优化问题
问题描述:minxf(x) s. t. g(x)≤0。
- 同样地,对于任意在 g(x)=0 平面上的 x,也一定有 ∇g(x) 垂直于平面,并且指向平面外。
- 对于一个局部最优解 x∗:
- 若其在平面上,则 −∇f(x∗) 的方向必须与 ∇g(x∗) 相同。
该条件等价于 ∃μ>0,s. t. ∇f(x∗)+μ∇g(x∗)=0。
- 若在内部,已经满足约束 g(x)≤0,则只需要满足 ∇f(x∗)=0 即可。
该条件等价于 ∃μ=0,s. t. λf(x∗)+μ∇g(x∗)=0。(为了跟上面凑成一样的形式)
- 所以,可以归结成:
- g(x∗)≤0;
- μ≥0;
- μg(x∗)=0(若 g(x) 的约束 active,则 g(x)=0,μ>0,若 inactive,则 g(x)<0,μ=0)
- ∇f(x∗)+μ∇g(x∗)=0
- 这四个条件称为 Karush-Kuhn-Tucker (KKT) 条件,为必要条件。
对其也可以定义拉格朗日方程:
L(x,μ)=f(x)+μg(x)
KKT 条件说明,若 x∗ 为局部最小值,则:
- ∇xL(x∗,μ)=∇f(x∗)+μ∇g(x∗)=0;
- g(x∗)≤0;
- μ≥0;
- μg(x∗)=0。
等式/不等式约束都有的优化问题
问题描述:minxf(x) s. t. hi(x)=0,∀i∈[k],gj(x)≤0,∀j∈[l]
拉格朗日函数(其中 λ,μ 分别为 k,l 维向量):
L(x,λ,μ)=f(x)+i∈[k]∑λihi(x)+j∈[l]∑μjgj(x)
其 KKT 条件:若 x∗ 为局部最小值,则必要条件为:
- ∇xL(x∗,λ,μ)=0(导数条件);
- ∀i∈[k] 有 hi(x∗)=0 以及 ∀j∈[l] 有 gj(x∗)≤0(可行性条件);
- ∀j∈[l] 有 μj≥0;
- ∀j∈[l] 有 μjgj(x∗)=0(互补松弛条件)。
还是有不等式条件,所以不一定能从 KKT 条件直接求出 candidate solutions。
SVM 原始形式推导
SVM 是一个线性分类器:f(x)=wTx+b,y∈{−1,1}(同样只是 index)。
回忆:数据点线性可分的时候逻辑回归无穷多解的情况。
SVM 有一个明确的准则选择“最好的”分隔超平面:寻找一个使得间隔(margin)最大的超平面。margin 被定义为数据点到超平面的最小距离(max-min problem)。思想为结构风险最小化(Structural Risk Minimization)
Margin 越大,泛化性越强,也对离群值(outliers)更健壮(robust)。
而且一定在超平面两边都有至少一个(可以用调整法证明)能够支持这个超平面的点(称为 Support Vectors)
注意到,支持向量是直接决定分隔超平面的,但其他的点完全不会对支持向量的决策产生任何影响(对应表达式中的 inactive 约束)。
显然,xi 到超平面的距离为
di=∥w∥∣wTx+b∣
推导?考虑垂足 x0,则可以有
{x0+di⋅∥w∥w=xiwTx0+b=0
注意这里的 di 带有方向的含义,我们改用 γi 表示。上式左乘 wT 即可配凑出 wTx0,可以用 −b 换掉,于是即推出
γi=∥w∥wTxi+b
取绝对值即得到 di 的式子。
也可以用拉格朗日乘子法。
相当于我们需要 x0min21∥xi−x0∥2 s. t. wTx0+b=0。
写出拉格朗日方程:
L(x0,λ)=21∥xi−x0∥2+λ(wTx+b)
求偏导有
{−(xi−x0)+λw=0wTx0+b=0
类似地,上式左乘 wT 可以解得 λ=∥w∥2wTxi+b
回代,∥xi−x0∥=∣λ∣∥w∥=∥w∥∣wTxi+b∣,与前面得到的结果一致。
事实上我们会更多关注 γi,因其带有方向信息。γi>0 代表点 xi 在 wTx+b>0 区域内,反之亦然。
定义
γiˉ=yiγi=∥w∥yi(wTxi+b)
可以通过 γiˉ 是否大于 0 判断一个点是否被正确分类(这里体现出一开始我们规定 yi∈{−1,1} 的好处),就不需要分类讨论正负类的 γi 大于还是小于 0 了。
而之前讨论的所谓 margin 就是
γ=i∈[n]minγiˉ
于是,我们之前说过的优化问题就变为:w,bmaxγ s. t. ∀i∈[n] 有 γiˉ≥γ。
约束条件改写一下,变为:∥w∥yi(wTxi+b)≥γ。
对于支持向量们,一定有 γiˉ=γ。假设 x0 是某个支持向量,则 ∥w∥y0(wTx0+b)=γ,用该式子替换掉 γ,优化问题变为 w,bmax∥w∥y0(wTx0+b) s. t. yi(wTxi+b)≥y0(wTx0+b)。
称 y0(wTx0+b) 为 functional margin,w,b 可以任意缩放使得其任意大或任意小(但这不影响 geometric margin)。
所以还不如直接令 y0(xTx0+b)=1,某种程度上是种正则化。
所以优化的表达式变为 w,bmax=∥w∥1 s. t. ∀i∈[n] 有 yi(wTxi+b)≥1。等价于 w,bmin21∥w∥2(该形式更方便进行求导),该形式称为 SVM 的原始形式(The Primal Form of SVM)
该形式强制令 functional margin = 1,yi(wTxi+b)≥1 而不是 ≥0 可以理解为要求所有的点到平面都有一个距离,以保证结构鲁棒性。
注意到这是一个二次规划(Quadratic Programming),有很多现成的标准包可以进行解决,具体的解决方法不在本节课的范围内。
剩余两个未能解决的问题:
- 不线性可分
- 线性可分但是有使得 margin 过于小的 outlier
考虑拉格朗日函数(习惯上用 α 而不是之前的 μ)
L(w,b,α)=21∥w∥2+i∈[n]∑αi(1−yi(wTxi+b))
定义
p∗=w,bminαi≥0maxL(w,b,α)
Claim:p∗ 为 SVM 主形式的一个解。
相当于我们将带约束的 SVM 主形式变成了不带约束的双层优化问题。
证明:假设某些约束没有被满足,则 ∃i 使得 1−yi(wTxi+b)>0,则里层优化会让 αi→+∞ 进而使得 αi≥0maxL(w,b,α)→+∞,所以外层的优化一定会让所有约束得到满足进而避免这种趋于正无穷的情况。
而里层的优化会使得 αi=0,所以最外层优化的就是我们需要的解。
这个形式可能不太好解,所以把他转换为对偶形式:
d∗=αi≥0maxw,bminL(w,b,α)
弱对偶定理:d∗≤p∗。
证明:注意到 w,bminL(w,b,α)≤L(w,b,α),∀w,b,即 d∗≤ai≥0maxL(w,b,α),∀w,b。所以 d∗≤w,bminαi≥0maxL(w,b,α)=p∗。
可以理解为两个人的博弈。最小的里面挑一个最大的一定小于等于在最大的里面挑一个最小的。
强对偶条件:d∗=p∗,则 strong duality holds. not in general,但是在 SVM 这里是成立的。
斯拉特条件(Slater’s Condition):当目标函数为凸,且约束为线性,则强对偶条件满足。(证明略)
回忆:
p∗d∗=w,bminαi≥0maxL(w,b,α)=αi≥0maxw,bminL(w,b,α)
证明弱对偶条件:假设 wp,bp 为 p∗ 的解,αd 为 d∗ 的解。则
p∗=w,bminαi≥0maxL(w,b,α)=α≥0maxL(wp,bp,α)≥L(wp,bp,αd)≥w,bminL(w,b,αd)=d∗
而我们知道,若强对偶条件成立,则 p∗ 与 d∗ 的解是一样的,即 (wp,bp,αd),即上面式子中所有的不等号都是等号。这告诉我们,可以通过解对偶问题 d∗ 来解原问题。
α≥0maxw,bminL(w,b,α)=21∥∥∥w2∥∥∥+i∈[n]∑αi−i∈[n]∑αiyi(wTxi+b)
先看里层的。由其凸性,进行求导,要求 ∂w∂L=0,∂b∂L=0
∂w∂L∂b∂L=w−∑αiyixi=0=−∑αiyi=0
这不就是 KKT 条件吗,原因就在于由于强对偶性,解是一样的,所以自然也需要满足 KKT 条件。
所以
w=i∈[n]∑αiyixii∈[n]∑αiyi=0
将其代入原来的式子,就有
α≥0maxw,bminL(w,b,α)=21∥∥∥w2∥∥∥+i∈[n]∑αi−i∈[n]∑αiyi(wTxi+b)=α≥0max21⎝⎛i∈[n]∑αiyixiT⎠⎞⎝⎛i∈[n]∑αiyixi⎠⎞+i∈[n]∑ai −i∈[n]∑αiyi⎝⎛i∈[n]∑αiyixiT⎠⎞Txi−bi∈[n]∑αiyi=α≥0maxi∈[n]∑αi−21i∈[n]∑j∈[n]∑αiαjyiyjxiTxj
subject to {αi≥0,∑aiyi=0,∀i∈[n]∀i∈[n],优化问题变为优化 n 个 αi,原来的原始形式则是优化 d+1 个变量。
假设将 α∗ 解出来了,考虑解 w∗,b∗:
首先显然
w∗=i∈[n]∑αiyixi
然后,对于支持向量 (xk,yk),有 yk(w∗Txk+b∗)=1,所以 b∗=yk−w∗Txk,这也告诉我们 yk1=yk。
然后对于 active 的约束,αi∗>0。
其实,只需要支持向量就够了。
w∗=(xi,yi) is a S.V.∑αi∗yixi
SMO 算法(sequential minimum optimization)
刚才我们是假设求解出来了对偶问题,现在考虑如何求解。
-
主要思路:迭代地更新 αi,而固定其他的 αj。
-
但是 ∑αiyi=0,所以若固定了其他的 n−1 个 αj,αi 就已经可以被确定了,所以不能简单地这样去做。
改进:每次挑两个 αi 和 αj,而固定其他的 n−2 个。注意到 αiyi+αjyj=−k=i,j∑αkyk=Constant。于是可以用 αi 表示 αj。
-
解这个一维的二次规划(另外 n−2 个被固定了,选的一个可以表示另一个),这自然是好解的,甚至有闭式解。
-
重复上述步骤,每次取 αi,αj,迭代到你想结束为止。
核技巧(Kernel Trick)
考虑对 xi 做变换 φ(xi)(可以是变换到高维空间)
然后便可以将 φ(xi)Tφ(xj)T 表示为 k(xi,xj),这表示了 xi 与 xj 的相似度。其实,原来的 xiTxj 也算一种核(线性核)
假设 x 为一维,但线性不可分。而用一个核函数 φ(x)=(x,x2),其就可以线性可分了:
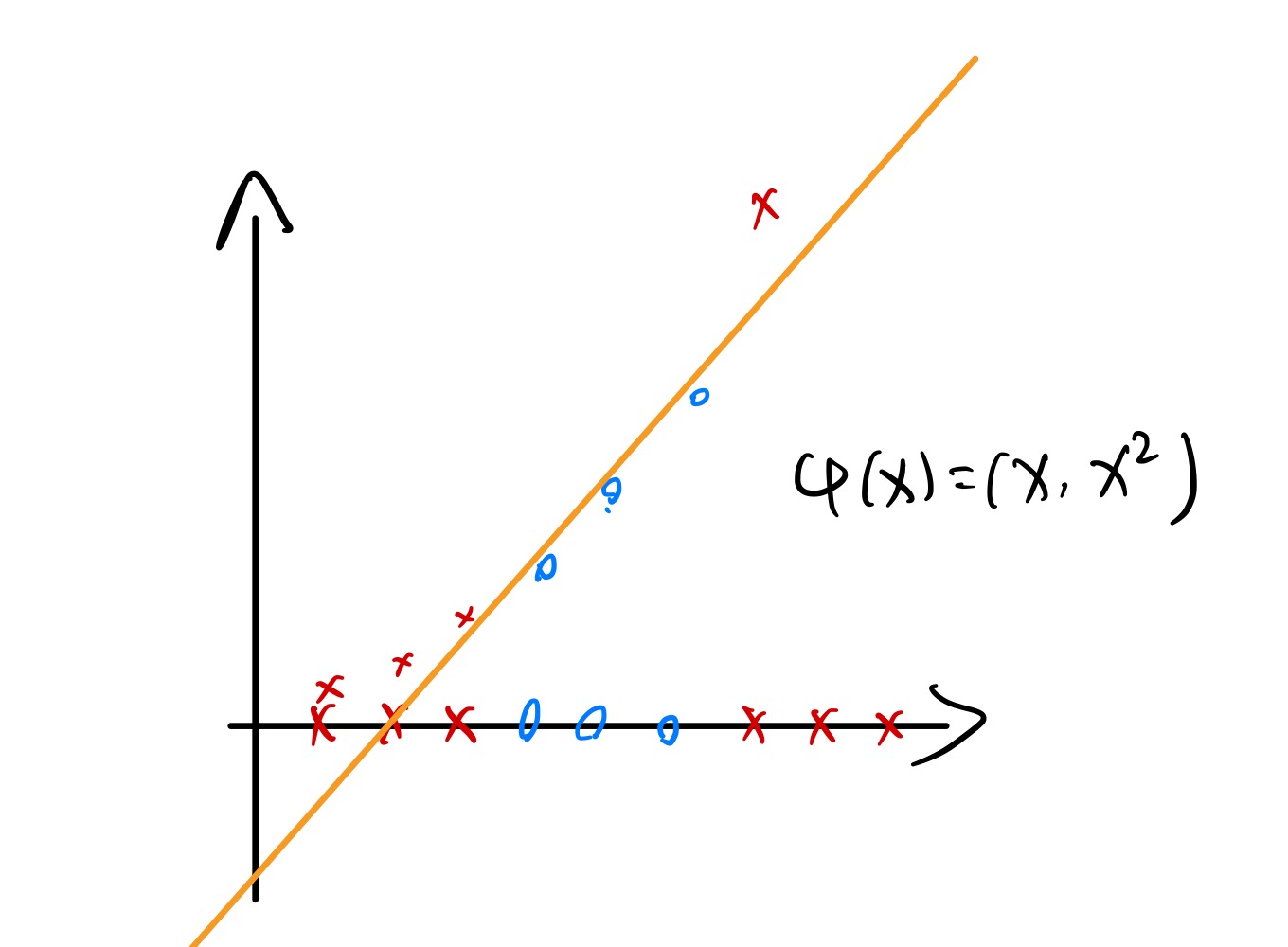
所以这就为我们提供了方便:把本来非线性可分原始数据用核函数进行升维,变为线性可分后用 SVM 求解,求解到的超平面还可以映射回原空间(当然就变得非线性了)
现在,考虑 x=(x1,x2)T∈R2,定义 φ(x)=(1,x1,x2,x12,x22,x1x2)∈R6,计算的时候有两种方法:
- 可以直接算所有的 φ(xi)Tφ(xj)∈R6,相当于先映射到高维空间后做计算,但这样计算的复杂度也会相应高;
- 在低维空间用 k(xi,xj) 直接把他们的相似度算出来(kernel trick),就不需要先把他们映射到高维空间了。
E. g. 考虑 x=(x1,x2)T,z=(z1,z2)T,定义核函数 k(x,z)=(xTz+1)2。展开:
k(x,z)=(xTz+1)2=(x1z1+x2z2+1)2=x12z12+x22z22+1+2x1z1+2x2z2+2x1z1x2z2=(1,2x1,2x2,x12,x22,2x1x2)T⋅(1,2z1,2z2,z12,z22,2z1z2)
那其实便可看出来 φ(x)=(1,2x1,2x2,x12,x22,2x1x2)T,若用了 kernel trick 显然就能达到更低的时间复杂度。
核函数合法性的判断:k(⋅,⋅) 合法仅当 ∃φ 使得 k(x,z)=φ(x)Tφ(z)T。显然一个输出负数的核函数绝对是不合法的。接下来介绍 Mercer Theorem:k(⋅,⋅) 合法当且仅当:
- 对称性:k(x,z)=k(z,x),∀x,z
- 核矩阵(kernel matrix, gram matrix)半正定
K:=⎣⎢⎢⎡k(x1,x1)⋮k(xn,x1)k(x1,x2)⋮k(xn,x2)⋯⋯k(x1,xn)⋮k(xn,xn)⎦⎥⎥⎤∈Rn×n
这里不打算证明,给出一个 intuition:K 对称且半正定所以肯定可以对角化,且所有特征值 ≥0。则 K=∑kλkμkμkT,Kij=∑kλkμkjμki,所以这样其实已经将 φ 给出。(不考)
常见的核函数:
- 线性核:k(x,z)=xTz;
- 多项式核:k(x,z)=(xTz+1)p,Rd→RO(min(pd,dp));
- 高斯核(RBF Kernel,radial basis function):
k(x,z)=exp(−2σ2∥x−z∥2)
高斯核相当于把 x 映射到无穷维空间然后做内积?考虑泰勒展开:
f(x)=f(0)+f′(0)x+2!f′′(0)x2+⋯
将 k(x,z) 写出来:
k(x,z)=exp(−2σ2∥x∥2)exp(−2σ2∥z∥2)exp(σ21xTz)
将最后一项进行泰勒展开:
=exp(σ21xTz)1+σ21xTz+2!1(σ2)2(xTz)2+3!1(σ2)3(xTz)3+⋯
后面是一堆多项式核的叠加!根据前面的定理,合法的核函数相加后仍然合法。
事实上,σ 是很重要的超参数。更大的 σ2 会使得高阶项迅速趋于 0,有效的维度就会降低;小的 σ2 有可能让任意的数据均可分,带来过拟合的风险,对 outlier 不健壮。
松弛变量(slack variables)
现在问题的关键在于如何处理离群点(outliers)。
之前,我们都是硬约束,即要求 ∀i,yi(wTxi+b)≥1。现在考虑软约束,引入松弛变量(slack variables)ξi。
现在约束变成 ∀i∈[n],yi(wTxi+b)≥1−ξi,其中 ξi≥0(允许超过 wTx+b=±1 一定距离 ξi)
但同时,肯定不能让 ξi 任意优化。我们肯定希望 ξi 尽可能小。优化问题变成:
w,b,ξmin21∥w∥2+C⋅i∈[n]∑ξi
s. t. yi(wTxi)≥1−ξi,ξi≥0,∀i∈[n]。其中 C 为调控 ξ 力度的参数。事实上这才是 SVM 实战中最常用的形式。
注意到 ξi≥max(0,1−yi(wTxi+b)),所以问题可以进一步化简:
w,bmin21∥w∥2+C⋅i∈[n]∑max(0,1−yi(wTxi+b))
这里是直接用 ξ 的下界去进行替换。而且注意到 max(0,1−yi(wTxi+b)) 其实为合页损失(hinge loss)。定义 zi:=yif(xi)
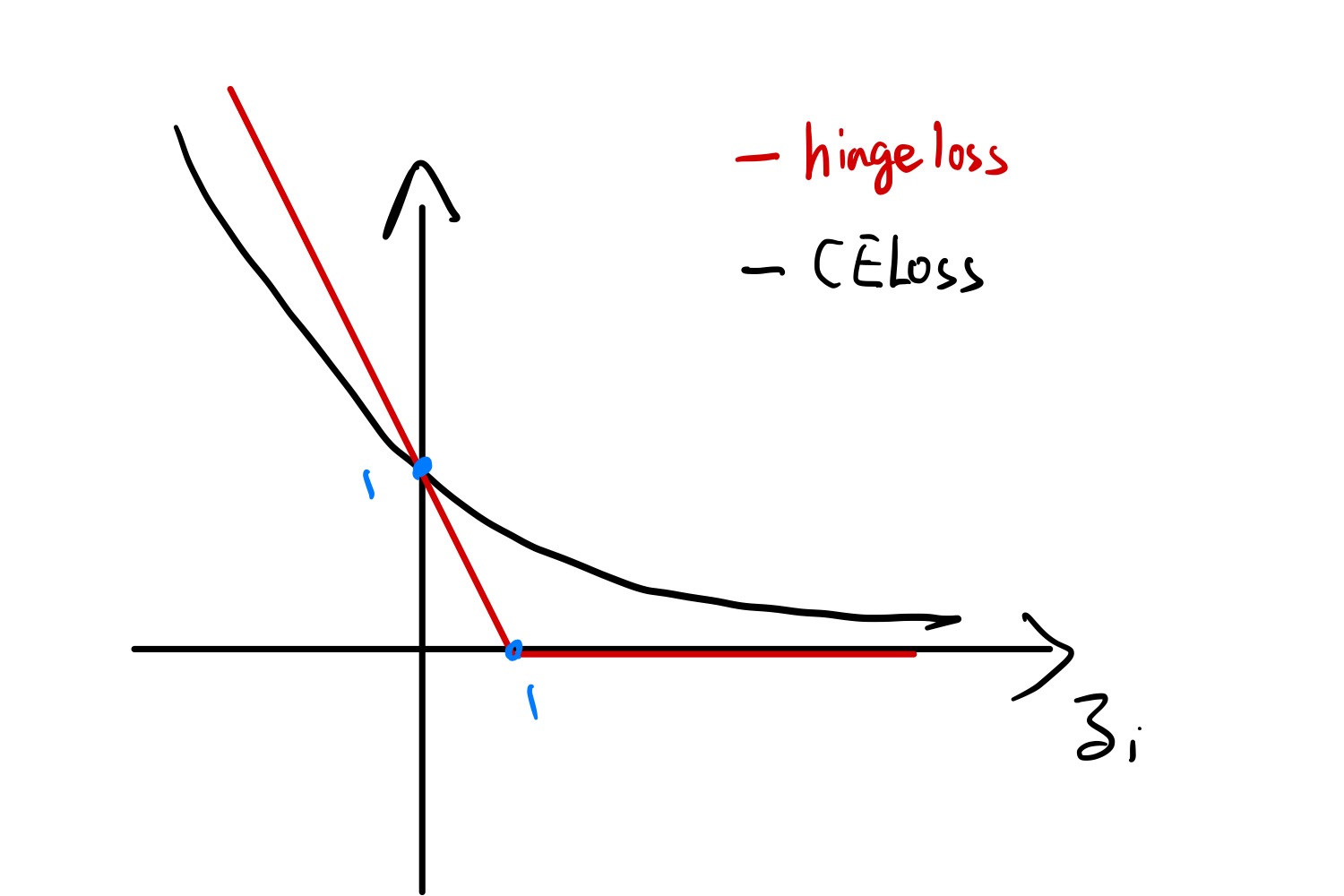
zi>1 的情况相当于点不产生贡献,zi<1 的情况就对应着 ξi>0 的情况,产生正比于 ξi 的 loss。而这个时候 ∥w∥2 就可以理解为正则化项了(倒反天罡)。