Last updated on October 17, 2024 10:46 PM
SVM 对偶形式 (cont.)
回忆:
p∗d∗=w,bminαi≥0maxL(w,b,α)=αi≥0maxw,bminL(w,b,α)
证明弱对偶条件:假设 wp,bp 为 p∗ 的解,αd 为 d∗ 的解。则
p∗=w,bminαi≥0maxL(w,b,α)=α≥0maxL(wp,bp,α)≥L(wp,bp,αd)≥w,bminL(w,b,αd)=d∗
而我们知道,若强对偶条件成立,则 p∗ 与 d∗ 的解是一样的,即 (wp,bp,αd),即上面式子中所有的不等号都是等号。这告诉我们,可以通过解对偶问题 d∗ 来解原问题。
α≥0maxw,bminL(w,b,α)=21∥∥∥w2∥∥∥+i∈[n]∑αi−i∈[n]∑αiyi(wTxi+b)
先看里层的。由其凸性,进行求导,要求 ∂w∂L=0,∂b∂L=0
∂w∂L∂b∂L=w−∑αiyixi=0=−∑αiyi=0
这不就是 KKT 条件吗,原因就在于由于强对偶性,解是一样的,所以自然也需要满足 KKT 条件。
所以
w=i∈[n]∑αiyixii∈[n]∑αiyi=0
将其代入原来的式子,就有
α≥0maxw,bminL(w,b,α)=21∥∥∥w2∥∥∥+i∈[n]∑αi−i∈[n]∑αiyi(wTxi+b)=α≥0max21⎝⎛i∈[n]∑αiyixiT⎠⎞⎝⎛i∈[n]∑αiyixi⎠⎞+i∈[n]∑ai −i∈[n]∑αiyi⎝⎛i∈[n]∑αiyixiT⎠⎞Txi−bi∈[n]∑αiyi=α≥0maxi∈[n]∑αi−21i∈[n]∑j∈[n]∑αiαjyiyjxiTxj
subject to {αi≥0,∑aiyi=0,∀i∈[n]∀i∈[n],优化问题变为优化 n 个 αi,原来的原始形式则是优化 d+1 个变量。
假设将 α∗ 解出来了,考虑解 w∗,b∗:
首先显然
w∗=i∈[n]∑αiyixi
然后,对于支持向量 (xk,yk),有 yk(w∗Txk+b∗)=1,所以 b∗=yk−w∗Txk,这也告诉我们 yk1=yk。
然后对于 active 的约束,αi∗>0。
其实,只需要支持向量就够了。
w∗=(xi,yi) is a S.V.∑αi∗yixi
SMO 算法(sequential minimum optimization)
刚才我们是假设求解出来了对偶问题,现在考虑如何求解。
-
主要思路:迭代地更新 αi,而固定其他的 αj。
-
但是 ∑αiyi=0,所以若固定了其他的 n−1 个 αj,αi 就已经可以被确定了,所以不能简单地这样去做。
改进:每次挑两个 αi 和 αj,而固定其他的 n−2 个。注意到 αiyi+αjyj=−k=i,j∑αkyk=Constant。于是可以用 αi 表示 αj。
-
解这个一维的二次规划(另外 n−2 个被固定了,选的一个可以表示另一个),这自然是好解的,甚至有闭式解。
-
重复上述步骤,每次取 αi,αj,迭代到你想结束为止。
核技巧(Kernel Trick)
考虑对 xi 做变换 φ(xi)(可以是变换到高维空间)
然后便可以将 φ(xi)Tφ(xj)T 表示为 k(xi,xj),这表示了 xi 与 xj 的相似度。其实,原来的 xiTxj 也算一种核(线性核)
假设 x 为一维,但线性不可分。而用一个核函数 φ(x)=(x,x2),其就可以线性可分了:
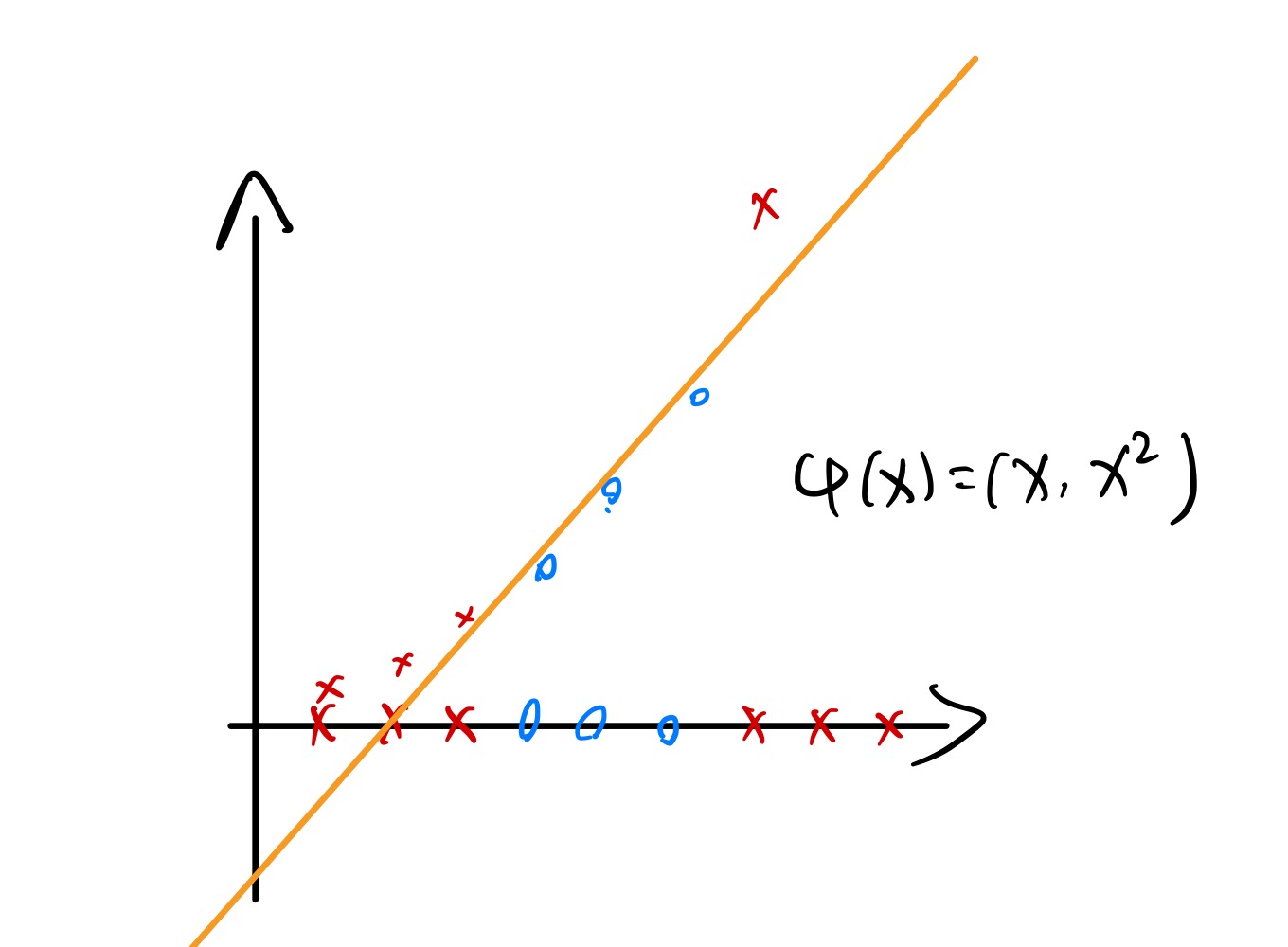
所以这就为我们提供了方便:把本来非线性可分原始数据用核函数进行升维,变为线性可分后用 SVM 求解,求解到的超平面还可以映射回原空间(当然就变得非线性了)
现在,考虑 x=(x1,x2)T∈R2,定义 φ(x)=(1,x1,x2,x12,x22,x1x2)∈R6,计算的时候有两种方法:
- 可以直接算所有的 φ(xi)Tφ(xj)∈R6,相当于先映射到高维空间后做计算,但这样计算的复杂度也会相应高;
- 在低维空间用 k(xi,xj) 直接把他们的相似度算出来(kernel trick),就不需要先把他们映射到高维空间了。
E. g. 考虑 x=(x1,x2)T,z=(z1,z2)T,定义核函数 k(x,z)=(xTz+1)2。展开:
k(x,z)=(xTz+1)2=(x1z1+x2z2+1)2=x12z12+x22z22+1+2x1z1+2x2z2+2x1z1x2z2=(1,2x1,2x2,x12,x22,2x1x2)T⋅(1,2z1,2z2,z12,z22,2z1z2)
那其实便可看出来 φ(x)=(1,2x1,2x2,x12,x22,2x1x2)T,若用了 kernel trick 显然就能达到更低的时间复杂度。
核函数合法性的判断:k(⋅,⋅) 合法仅当 ∃φ 使得 k(x,z)=φ(x)Tφ(z)T。显然一个输出负数的核函数绝对是不合法的。接下来介绍 Mercer Theorem:k(⋅,⋅) 合法当且仅当:
- 对称性:k(x,z)=k(z,x),∀x,z
- 核矩阵(kernel matrix, gram matrix)半正定
K:=⎣⎢⎢⎡k(x1,x1)⋮k(xn,x1)k(x1,x2)⋮k(xn,x2)⋯⋯k(x1,xn)⋮k(xn,xn)⎦⎥⎥⎤∈Rn×n
这里不打算证明,给出一个 intuition:K 对称且半正定所以肯定可以对角化,且所有特征值 ≥0。则 K=∑kλkμkμkT,Kij=∑kλkμkjμki,所以这样其实已经将 φ 给出。(不考)
常见的核函数:
- 线性核:k(x,z)=xTz;
- 多项式核:k(x,z)=(xTz+1)p,Rd→RO(min(pd,dp));
- 高斯核(RBF Kernel,radial basis function):
k(x,z)=exp(−2σ2∥x−z∥2)
高斯核相当于把 x 映射到无穷维空间然后做内积?考虑泰勒展开:
f(x)=f(0)+f′(0)x+2!f′′(0)x2+⋯
将 k(x,z) 写出来:
k(x,z)=exp(−2σ2∥x∥2)exp(−2σ2∥z∥2)exp(σ21xTz)
将最后一项进行泰勒展开:
=exp(σ21xTz)1+σ21xTz+2!1(σ2)2(xTz)2+3!1(σ2)3(xTz)3+⋯
后面是一堆多项式核的叠加!根据前面的定理,合法的核函数相加后仍然合法。
事实上,σ 是很重要的超参数。更大的 σ2 会使得高阶项迅速趋于 0,有效的维度就会降低;小的 σ2 有可能让任意的数据均可分,带来过拟合的风险,对 outlier 不健壮。
松弛变量(slack variables)
现在问题的关键在于如何处理离群点(outliers)。
之前,我们都是硬约束,即要求 ∀i,yi(wTxi+b)≥1。现在考虑软约束,引入松弛变量(slack variables)ξi。
现在约束变成 ∀i∈[n],yi(wTxi+b)≥1−ξi,其中 ξi≥0(允许超过 wTx+b=±1 一定距离 ξi)
但同时,肯定不能让 ξi 任意优化。我们肯定希望 ξi 尽可能小。优化问题变成:
w,b,ξmin21∥w∥2+C⋅i∈[n]∑ξi
s. t. yi(wTxi)≥1−ξi,ξi≥0,∀i∈[n]。其中 C 为调控 ξ 力度的参数。事实上这才是 SVM 实战中最常用的形式。
注意到 ξi≥max(0,1−yi(wTxi+b)),所以问题可以进一步化简:
w,bmin21∥w∥2+C⋅i∈[n]∑max(0,1−yi(wTxi+b))
这里是直接用 ξ 的下界去进行替换。而且注意到 max(0,1−yi(wTxi+b)) 其实为合页损失(hinge loss)。定义 zi:=yif(xi)
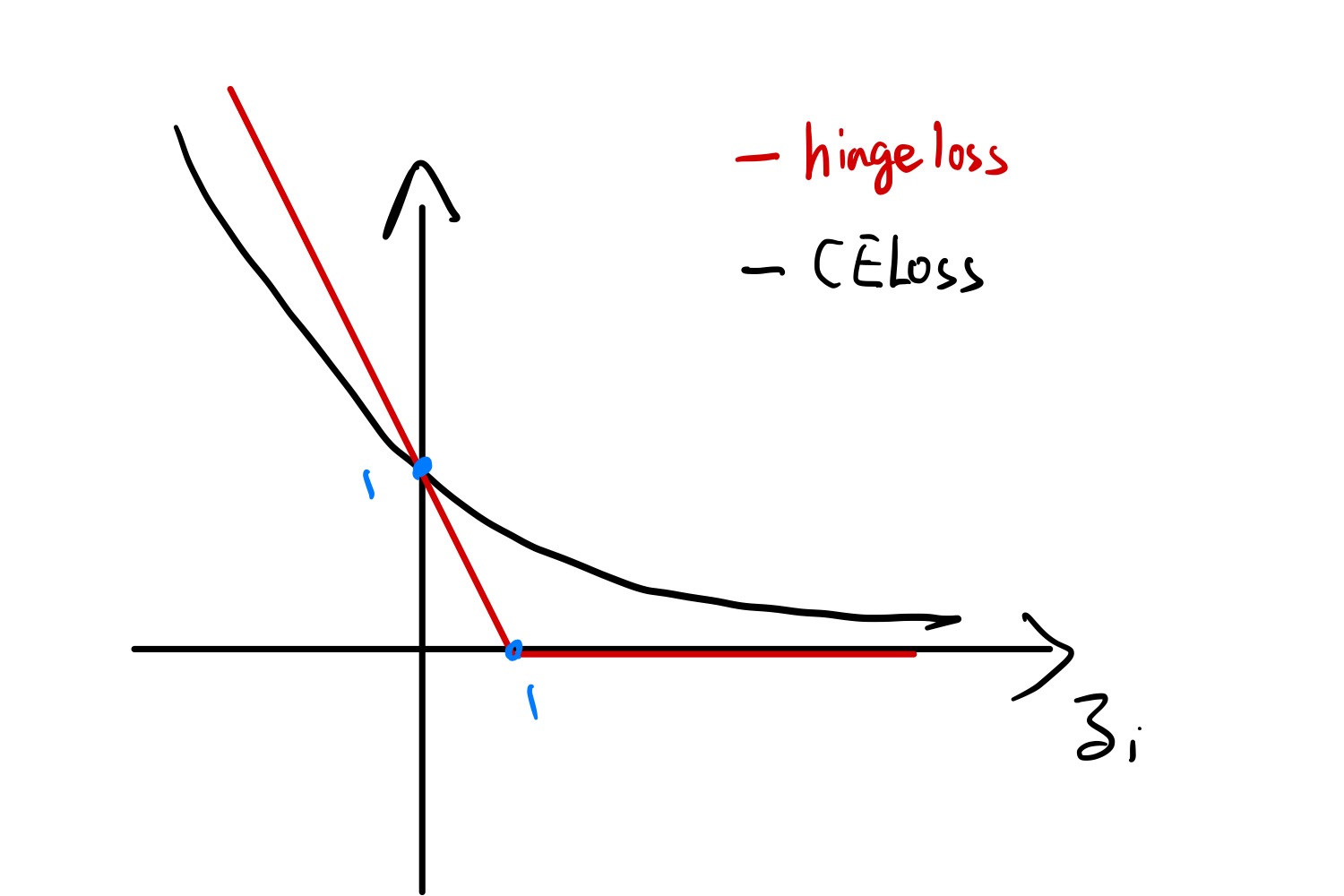
zi>1 的情况相当于点不产生贡献,zi<1 的情况就对应着 ξi>0 的情况,产生正比于 ξi 的 loss。而这个时候 ∥w∥2 就可以理解为正则化项了(倒反天罡)。