Last updated on December 20, 2025 9:30 PM
本文主要涉及高斯过程相关的推导以及应用。
一键回城。
作者的概率统计知识相当菜,在课后费了好大劲才搞懂这一节的内容,如有错误欢迎随时指出,吾必当感激不尽!
多元高斯分布(Multivariate Gaussian Distribution)
考虑多元高斯分布
N(x∣μ,Σ)
μ∈Rd 为均值,Σ∈Rd×d 为协方差矩阵。Σij=Cov(xi,xj)=E[(xi−μi)(xj−μj)]=E[xixj]−E[xi]E[xj]。
概率密度函数:
(2π)2d1∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ))
d=1 的时候,μ∈R,Σ=σ2,概率密度函数为
N(x∣μ,σ2)=2πσ21exp(−2σ21(x−μ)2)
与我们学过的一维的形式是相同的。
当 Σ 为对角阵的时候,说明各维度之间互相独立,联合分布就可以拆开:
N(x∣μ,Σ)=n=1∏d2πσi21exp(−2σi2(xi−μi)2)
性质:
E[x]=∫XxN(x∣μ,Σ)dx=μ
Cov[x]=⎣⎢⎢⎡Cov(x1,x1)⋮Cov(xd,x1)Cov(x1,x2)⋮Cov(xd,x2)⋯⋯Cov(x1,xd)⋮Cov(xd,xd)⎦⎥⎥⎤=E[xxT]−E[x]E[xT]=Σ
PRML 2.3
随机过程(Stochastic Process)
定义:A collection of (infinitely) random variables along an index set.
Index set 可以为 N,R,Rd。其可以在描述时间,但更一般性的描述下其也不一定是时间。
考虑 index xi,xi 对应的随机变量采样得到 yi。当有无限多组 {(xi,yi)} 时候可以确定一个函数 y(x) 的分布,每次采样会得到一个确定的函数 y(x)。
为了确定一个随机过程,我们只需要确定其包含的所有随机变量的联合分布(joint distribution)注意,这些随机变量大概率是不独立的。
例 1:伯努利过程(扔硬币)
{y1,y2,⋯,yn},yi∼Ber(p)
Joint distribution: P(y1),⋯,P(yn)=P(y1)P(y2)⋯P(yn)
接下来看一个有意思些的
例 2:Markov 随机过程
{y1,y2,⋯,yT},一般认为建立在时间序列上。P(yt+1∣y1,⋯,yt)=P(yt+1∣yt)。
注意到 P(y1,⋯,yT)=P(y1)P(y2∣y1)P(y3∣y1,y2)⋯ 是肯定对的,无论有无条件独立性的假设。
而在 Markov 过程中,yt+1 是与 y1,⋯,yt−1 无关的,而只与 yt 有关。
所以,若有 Markov 的性质,我们就有 P(y1,⋯,yT)=P(y1)P(y2∣y1)P(y3∣y2)⋯P(yT∣yT−1)
高斯过程(Gaussian Process)
定义与求解推导
joint distribution over any finite collection of R.V.s to be Gaussian.
考虑任意 ∀{x1,x2,⋯,xn}⊆X,其中 X 为标号集合,则其对应的随机变量 {y1,y2,⋯,yn} 为高斯过程当且仅当 y1,⋯,yn 服从高斯分布。
为了确定一个高斯过程,我们可以对于每个随机变量 yi,确定其 μi,以及对于每个 i,j 对,确定 Σij。但是如果随机变量的个数很多,而且再考虑往里面添加新的随机变量的话,需要确定的参数数量就会呈指数级爆炸。所以我们希望有一种 consistent 的方式来进行求解。
考虑求出两个函数 m(⋅),k(⋅,⋅),其以随机变量 yi 对应的下标 xi 作为输入(不能以随机变量作为输入,毕竟我们就想要的是均值和协方差),分别输出 μi 和 Σij。
其实这个 k(⋅,⋅) 就是核函数,考虑到核函数的含义是给出两个向量的相似度,在这里就可以变相地说明 yi 和 yj 的相似程度——下标 xi,xj 越接近,yi,yj 越相关,这也是很符合直觉的(geometric meaning)。
有了这两个函数之后,我们就可以将一个高斯过程写成
y(x)∼GP(m(x),k(x,x′))
一般而言,我们都直接令 m(x)=0(回忆贝叶斯角度下的线性回归),在无关于 y 的先验知识下令均值为 0 是很符合 Occam’s Razar 原理的。
同时,Σ 应该是正定的。合法的核函数已经满足其半正定性。如果出现了有特征值为 0 的情况,可以通过添加 λI 噪声来进行解决。
考虑求解 k。我们其实一般使用 RBF kernel:
k(xi,xj)=exp(−2l2∥xi−xj∥2)
令 K 为 n 个训练点 x1,⋯,xn 对应的 Gram 矩阵,其中 Kij=k(xi,xj),K∈Rn×n,然后令 y:=[y1,⋯,yn]T 为 n 维随机变量。
则我们有 P(y)=N(y∣0,K),其为训练数据的标签的联合分布。
但是光有这个没有用,对于训练数据,我们是知道 GT 的,即知道每个 yi 分别是什么,我们更需要的是给定一个新的测试点 x∗,求出 P(y∗∣y)。
先考虑求出 y∗ 与 y 的联合分布。这还是比较容易的:
P([y∗y])=N([y∗y]∣0,[k(x∗,x∗)k(x∗)k(x∗)TK])
其中,k(x∗)=[k(x∗,x1),⋯,k(x∗,xn)]T。但这并不够,我们要的是条件分布而不是联合分布。
根据高斯分布相关性质,不加证明地,我们知道,这个条件分布仍是高斯分布:
P(y∗∣y)=N(y∗∣μ∗,Σ∗)
这意味着我们只需要确定 μ∗ 和 Σ∗ 即可。接下来利用高斯分布的一些结论(同样不加证明地):
Standard Conclusions from Gaussian
对于一个随机变量
X=[xaxb]∼N([μaμb],[ΣaaΣbaΣabΣbb])
其中 xa∈Ra,xb∈Rb,即把 a+b 维拆开来。
- 边缘化(marginalization):
xaxb∼N(μa,Σaa)∼N(μb,Σbb)
- 条件分布:
P(xa∣xb)=N(xa∣μa∣b,Σa∣b)
其中μa∣bΣa∣b=μa+ΣabΣbb−1(xb−μb)=Σaa−ΣabΣbb−1Σba
这个式子会在之后的部分反复用到。
补充:张老师关于该式子物理含义的理解
考虑 μa∣b:该式子在描述在标准化意义下,xb 偏离其均值有多大。除以 Σbb 相当于在做标准化,而 Σab 的含义为 xa 与 xb 倾向于一起怎么样变动。xb 偏离均值越大,相应地对 μa 影响也会越大。
对于 Σab:确定了 xb 之后,xa 的“不确定度”就会减小,所以 Σaa 后面跟着的是减号。减小的程度与 xa,xb 的相关程度也是成正比的——越相关,确定 xb 后就“越能确定” xa,但还是会反比于 xb 的“不确定度”——若 xb 本身不确定程度就很大,那么观察到后对 xa 的影响也就应该没那么大。
对其有直觉上的理解可以方便记忆。
那么直接套这个结论,就可以很快求出我们要的结果了:
μ∗Σ∗=k(x∗)TK−1y=k(x∗,x∗)−k(x∗)TK−1k(x∗)
有没有发现什么问题?K 不一定是可逆的。回忆之前学过的知识,遇到这种情况我们一般会想办法弄成 (K+λI) 的形式,这样就一定可以求逆了。在线性回归的时候,我们添加了一个正则化项让这个形式 make sense 了,而此时我们也需要想一个让这个形式变得合理的办法。
Noise Setting
在之前,我们是假设观测到了 y 的 ground truth (GT)。现在我们假设 y 是带有噪声的,即 y^=y+ε,其中 ε∼N(0,σ2I)。接下来重新推导 y∗ 与 y^ 的联合分布与条件分布。
高斯分布有特别好的性质:对其做组合/线性变换后仍为高斯分布。所以 P([y∗,y^]T) 仍为高斯分布。
均值是简单的,仍是 0(因为添加的噪声项的均值为 0),而协方差矩阵就需要思考一下了:k(x∗,x∗) 不变,但 k(x∗) 和 K 就会发生改变了,我们用协方差的定义去推导:
Cov(y∗,yi^)=E[y∗yi^]−E[y∗]E[yi^]=E[y∗yi^]=E[y∗(yi+ε)]=E[y∗yi]+E[y∗]E[ε]=E[y∗yi]=Cov(y∗,yi)+E[y∗]E[yi]=Cov(y∗,yi)=k(y∗,yi)
所以 k(x∗) 还是不变的!接下来看 K:
Cov(yi^,yj^)=E[yi^yj^]−E[yi^]E[yj^]=E[(yi+εi)(yj+εj)]=E[yiyj]+E[yiεj]+E[yjεi]+E[εiεj]=k(xi,xj)+σ21(i=j)
所以得到结论:
P([y∗y^])=N([y∗y^]∣0,[k(x∗,x∗)k(x∗)k(x∗)TK+σ2I])
这正是我们想要的——所以条件分布也可以写出来了:
P(y∗∣y^)=N(y∗∣k(x∗)T(K+σ2I)−1y^,k(x∗,x∗)−k(x∗)T(K+σ2I)−1k(x∗))
其可以避免数值问题,提高计算稳定性。实际应用中也都是这个形式。
高斯过程视角下的岭回归
考虑岭回归:
wmin{(yi−wTφ(xi))2+λwTw}
假设观测到的 yi 有噪声。
从贝叶斯的视角来看,w 也是随机变量,给出其先验分布:
w∼N(0,σw2I)
再看看 yi:
yi=wTφ(xi)+εi
φ(xi) 为确定的值,w 为随机变量,εi 也为随机变量,所以 yi 也是随机变量!更进一步地,我们注意到 yi 也服从高斯分布(因为其为服从高斯分布的随机变量的线性组合)
所以,我们可以将 y 理解成高斯过程。
推导 y 对应的 m(⋅) 和 k(⋅,⋅) 吧。自然我们假设 m≡0。
Cov(yi,yj)=E[yiyj]−E[yi]E[yj]=E[(wTφ(xi)+εi)(wTφ(xj)+εj)]=E[φ(xi)TwwTφ(xj)]+E[εiεj]
对于 E[εiεj],我们知道其为 σ21(i=j)。又发现 Cov(w)=E[wwT]−E[w]E[wT],后者均为 0,所以
Cov(yi,yj)=φ(xi)Tσw2Iφ(xi)=σw2k(xi,xj)
所以
y∼N(0,σw2K+σ2I)
套用之前的结论就可以得到,若给一个 x∗,要预测 y∗,则
y∗∣y∼N(σw2k(x∗)T(σw2K+σ2I)−1y,σw2k(x∗,x∗)−σw4k(x∗)T(σw2K+σ2I)−1k(x∗))
所以高斯过程可以理解成线性回归的一个 kernel 版本,就也可以使用核技巧了。(可以类比一下 SVM)
其经常可以用来在非线性的情况下做一些回归问题,这种回归称为高斯过程回归(GPR)
应用
一些小细节:
- y∗ 可以是一个点,也可以是一个向量(即我们一次性预测很多个点)
- 和之前学习的回归模型不同,我们得到的是关于 y∗ 的一个分布。我们可以用其均值直接给出输出,也可以利用方差给出一个置信区间。
- σ 为超参数。
最常用的核函数就是 RBF 核:
k(x,x′)=exp(−2l2∥x−x′∥2)
其中 l 为 length scale,为超参数,此处不展开。
高斯过程回归(GPR)
假设下标集合为一维。并且有 6 个训练样本(y^ 的 GT 在下图中用红点标出)。
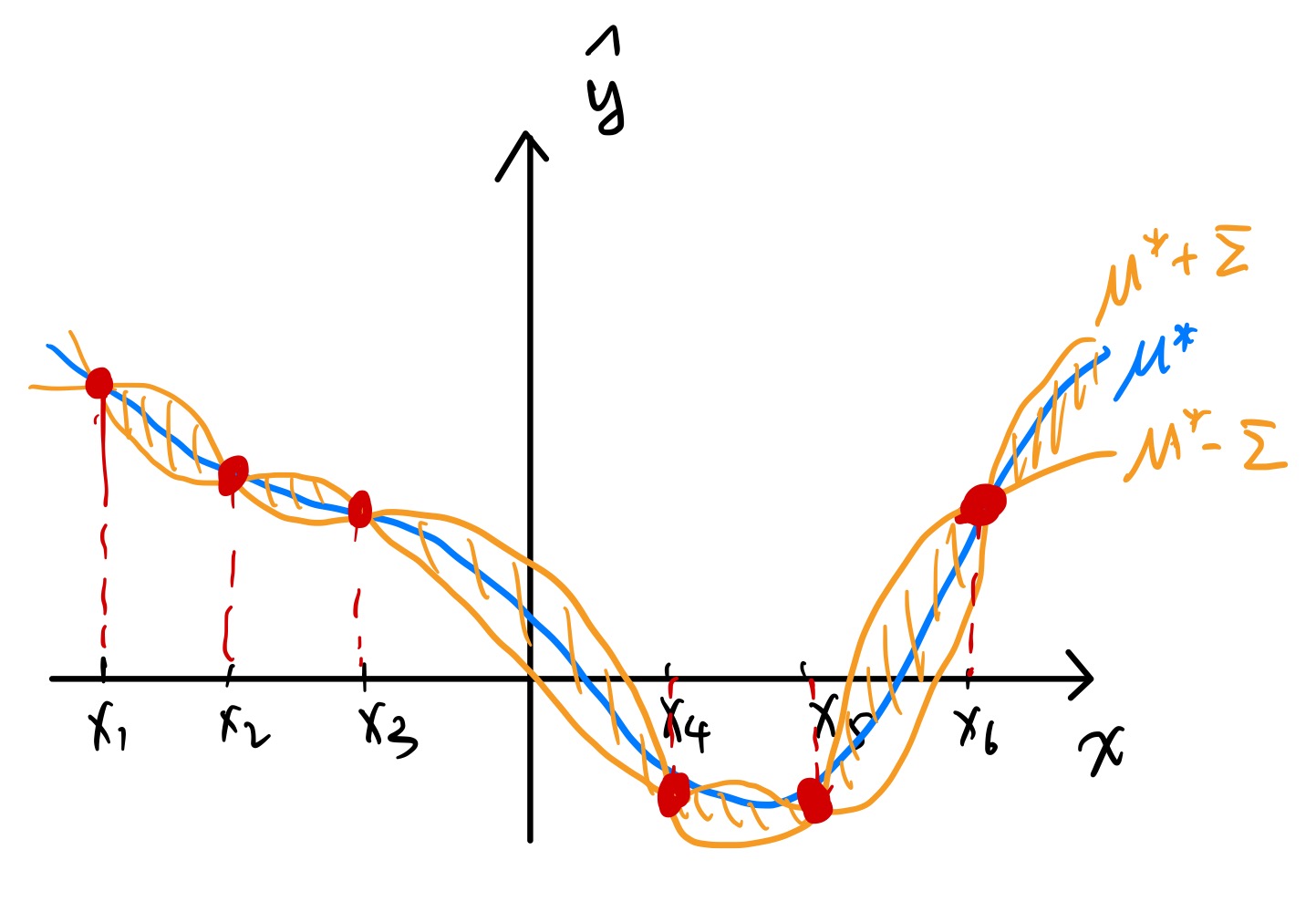
对这六个训练样本做 GPR,可以得到一条 μ∗ 关于 x∗ 的平滑曲线(蓝色标出),然后同时也可以画出标准差的图像,在上图中可以清晰看到离训练点越近,预测结果的置信度就越高(这也是很符合直觉的)
需要注意的是,μ∗ 未必穿过所有数据点。只有当 σ2=0,l→0 时,μ∗ 才会恰好穿过所有数据点。
推导:令 x∗=xn,k(x∗,x∗)=1,且由于 l→0,∀x=x∗ 有 k(x∗,x)=0,所以 K=I。此时 μ∗=k(x∗)TIy=yn。
贝叶斯优化(Bayesian Optimization, BO)
先介绍黑箱优化(black-box optimization),其目标函数是没有解析形式的,更不用提梯度了。传统的梯度下降法对于黑箱优化是无效的。
我们只能做的是,不断喂进去 x,然后观测其输出的 y。现在的目标就是在尽可能少的次数下使得 y 最大化。神经网络的超参数调参就是一种典型的黑箱优化问题。
误区:可能会觉得神经网络不是可以用梯度下降优化吗?
注意我们这里讨论的是超参数,神经网络最后输出的 performance 是无法被写成超参数的解析形式的。
贝叶斯优化的流程如下:
- 随机采样若干点,并扔进黑箱求值,得到初始的 {(xi,yi)};
- 用这些点做一个 GPR;
- 在回归结果的基础上,利用采集函数(acquisition function)a(x) 来选择新的一批点,并将这些点加入已知训练点,重新做 GPR;
- 重复第三步直到满足某种停止条件。
采集函数扮演着非常重要的角色,常见的有如下几种:
- Expected Improvement (EI):a(x)=E[(y(x)−ymax)+],寻找期望意义下能给 ymax 带来最大改进的点。
- Upper Confidence Bound:a(x)=μ(x)+κσ(x)。和 MCTS 里面的那个很像,相当于在平衡利用(exploitation)和探索(exploration)。
超参数调整软件推荐:optuna
Acknowledgement