Last updated on December 20, 2025 9:30 PM
一键回城。
概览
核心思想:将若干(弱)的模型组合在一起以获得一个强的模型。这些模型需要尽可能 diversed(因为如果都一样的话就起不到增强的效果了)
回顾偏差-方差分解:
ED[(f(x;D)−y)2]=ED[(f(x,D)−f(x))2]+(f(x)−y)2
高方差低偏差的模型:树模型,神经网络;低方差高偏差的模型:线性模型。
集成学习模型一般可以分为 Bagging 和 Boosting 两类。
Bagging
Bagging 的目的是减少方差,所以被集成的模型一般为高方差低偏差的模型。
理想情况下,假设我们可以从分布 P(D) 中反复采样训练集 D,然后令 f(x)=T1t∈[T]∑f(x;Dt)。可以发现当 T→∞ 的时候 f(x)→fˉ(x),于是方差也会 →0。
然而,实际上我们只有一个 D,所以无法做到从 P(D) 中反复采样。解决方案为 Bootstrap(自举)
Bootstrap
流程:
- 从 D 中有放回地抽样 n 个点(为什么是有放回,因为考虑到如果是无放回的话,每次的结果都是一样的了);
- 重复第一步 T 次,得到 D1^,D2^,⋯,D^T;
- f^(x)=T1t∈[T]∑f(x;D^t)
考虑一个简单的小问题:计算一个点 (xi,yi) 没有在 Dt^ 中的概率,以及当 n→∞ 时,其极限是多少。
显然
p=(1−n1)n→e1≈36.8%(n→∞)
所以平均来看,每个 D^t 只会包含 D 中 63.2% 的数据,我们可以将剩下的未被包含进去的数据作为 hold-out validation set(也叫做 out of bag set)
需要注意的是,Bootstrap 是没有理论保证的,但是经验上来看其确实能有效减小测试误差。
No model is correct, but some models are useful
随机森林(Random Forest)
其为最成功的 bagging 模型——“对于简单分类任务,必须尝试的一个模型”。
12345678910Input. Training data D, features F, number of trees TOutput. A model consisting of T decision treesMethod. B←An empty arrayfor t←1 to T doSample n points Dt^ from D with replacementSample d′<d features F′ from F without replacementBuild a full decision tree on D^t,F′ (can do some prowing to minimize out-of-bag error)end forAverage all decision trees to get final model
注意其强大之处来源于每棵决策树的 feature 集合也都是不同的!
简单,容易实现,非常强大。
Boosting
与 bagging 相对地,boosting 的核心在于减小偏差,所以一般选用低方差高偏差的模型,如线性模型或限制了树高的树模型。
AdaBoost
考虑做二分类问题。D={(x1,y1),⋯,(xn,yn)},y∈{−1,+1},x∈Rd。
输入:D 以及一个弱的学习算法 A(例如线性模型,AdaBoost 就可以让若干个线性模型集成为一个可以做非线性分类的模型)。
- 初始化采样权重(每一个数据点的权重):Wi(1)=Wi(1)=n1,i∈[n]。
- For t∈[T]:
- 用 D 和 {Wi(t)} 训练得到一个模型 ft(x):Rd→{−1,+1}。
- 计算 ft(x) 在 D 上的带权分类误差(weighted classification error)et=i∈[n]∑Wi(t)1(f(xi)=yi)
- 计算 ft(x) 的权重 αt:αt=21loget1−et。这个权重是在最终组合的时候的权重,et 越大,αt 越小,符合直觉。且 et>0.5 时 αt<0(把一半以上的数据都预测错了,那不如直接把输出取反)
- 更新数据点的权重 Wi(t+1)=Wi(t)⋅exp(−αtyift(xi)),归一化得到 Wi(t+1)=∑j∈[n]Wj(t+1)Wi(t+1)
考虑 exp(−αtyift(xi)) 这个式子的含义:一般而言 αt 为正(et>0.5 还是比较罕见的),则这个式子就是在考虑 yi 和 ft(xi) 是否同号。若同号,说明 ft 预测对了,则 exp 括号中的内容为负,对应着在接下来的训练中 (xi,yi) 的权重会减小;反之若异号,则 ft 预测错误,exp 括号内为正,对应着权重会增加。事实上 αt 为负的时候也不影响正确性,因为 αt<0 意味着已经对模型“取反”。
- 将 T 个 ft(x) 线性地组合起来:g(x)=t∈[T]∑αtft(x),g(x)≥0 时输出 1,反之输出 −1。
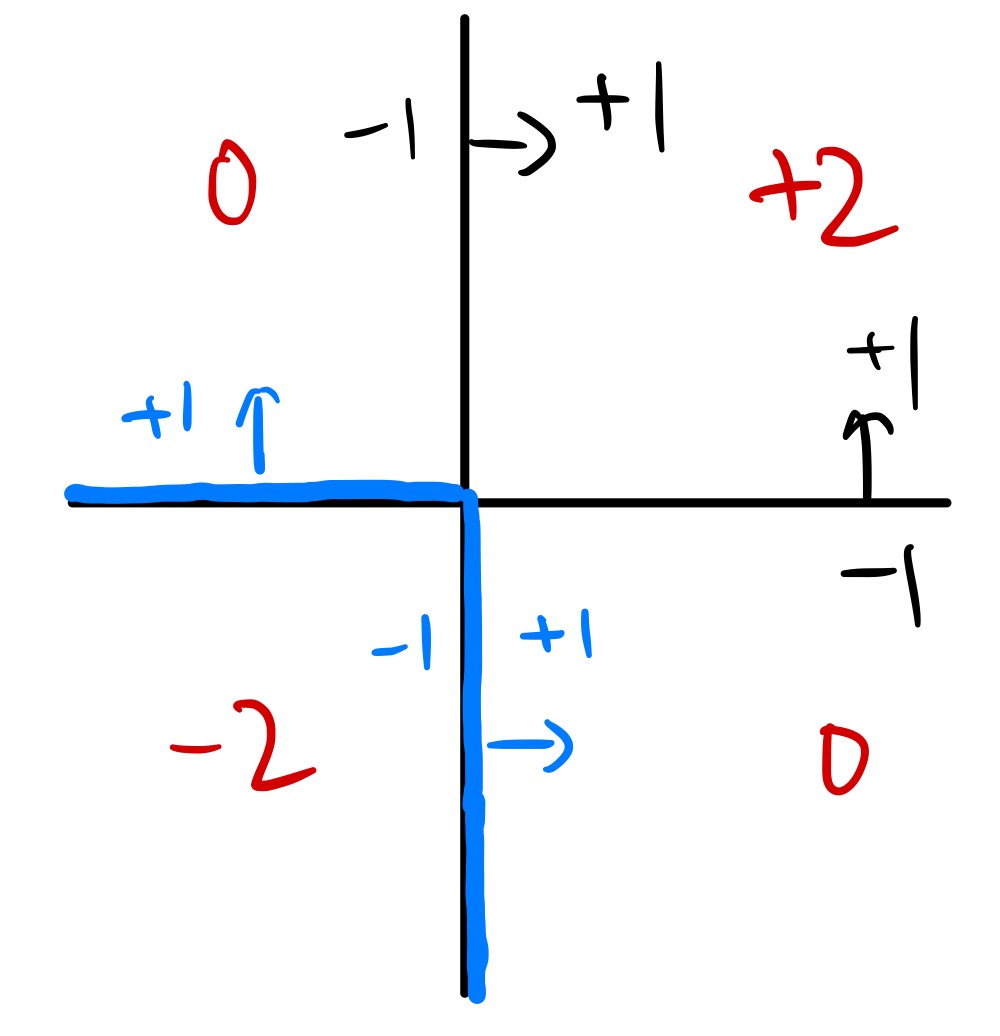
例如:如下图中,利用 AdaBoost 后得到两个分类器,分别为水平/竖直,且其权重相等,则组合后 g 的输出结果为红色所示,得到的最终分隔的边界为蓝色所示,可以发现其变为非线性的了。
加性模型(Additive Model)
是 boosting 的一种通用范式。
g(x)=t∈[T]∑αtft(x)
定义
gt(x)=j∈[t]∑αjfj(x)
在第 t 步,固定 gt−1(x),通过最小化某个损失函数来学习 αt,ft(x)。该损失函数为
i∈[n]∑L(yi,gt−1(xi)+αtft(xi))
最终 g(x)=gT(x)。大概含义就是,每次迭代只更新一个模型,同时计算损失函数的时候也考虑前面已经训练好了的模型。
AdaBoost 就是一种特殊的加性模型,其使用的损失函数为指数损失函数(exponential loss)L(y,f(x))=exp(−yf(x))
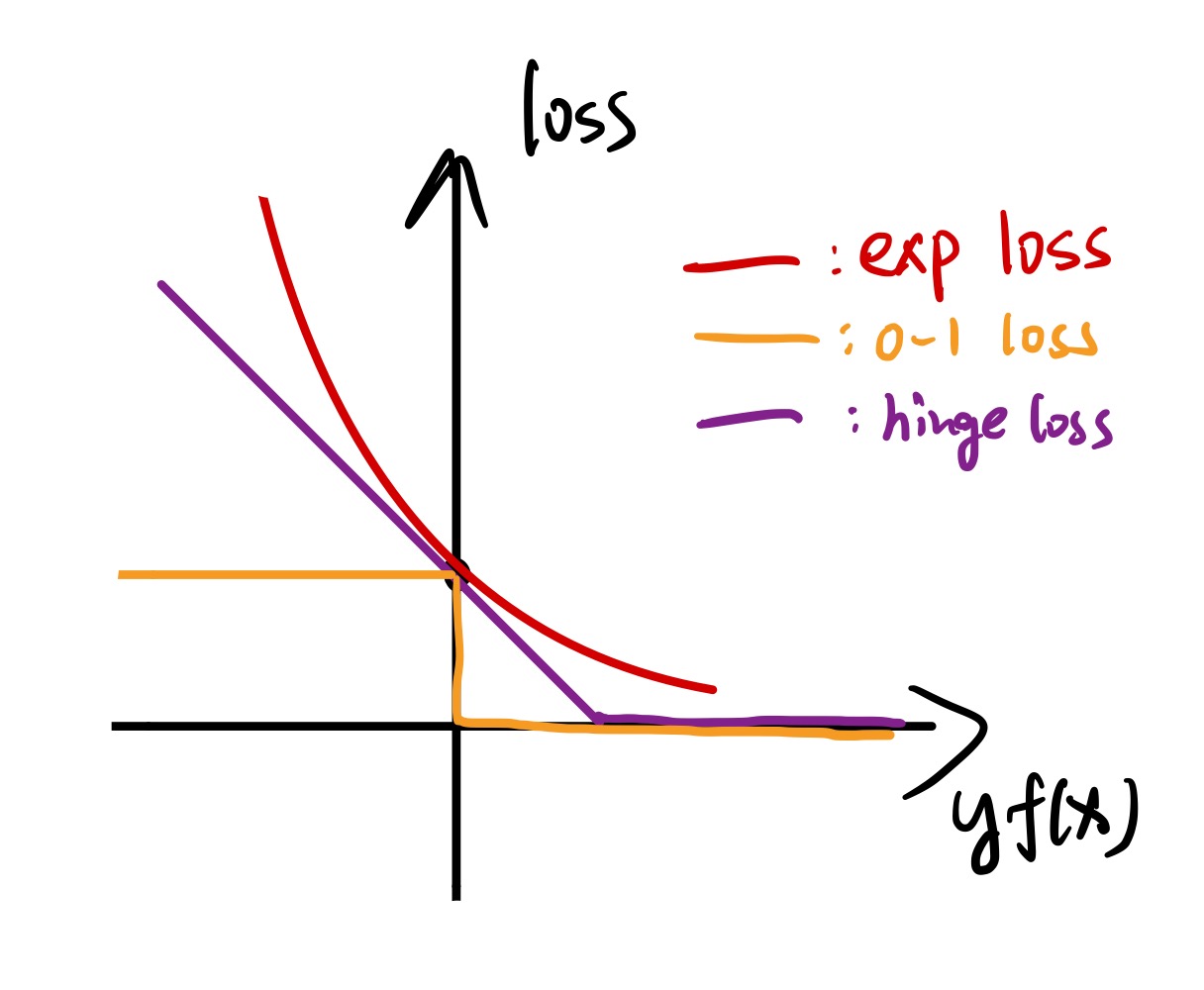
其是 hinge loss 和 0-1 loss 的替代(或者说上界),而且在 yf(x)<0 的时候增长地非常快。不过在 AdaBoost 里面,由于 yf(x) 的取值只有 ±1,所以损失函数的取值只可能为 e 或 1/e。(存疑)
AdaBoost 的推导
在第 t 步的时候,我们已经有 gt−1(x)=j∈[t−1]∑αjfj(x)。
我们现在需要优化
αt,ftmini∈[n]∑exp(−yi(gt−1(xi)+αtft(xi)))
定义 Wi(t):=exp(−yigt−1(xi)),事实上这个东西就是我们刚才的那个权重:
exp(−yigt−1(xi))=j∈[t−1]∏exp(−yiαjfj(xi))=Wi(t−1)⋅exp(−yiαt−1ft−1(xi))
可以发现和之前的定义是一致的。原来的最优化问题可以拆成:
αtminftmini∈[n]∑Wi(t)⋅exp(−yiαtft(x))
Claim:归一化后的 Wi(t) 与 Wi(t) 只相差常数,所以在最优化问题中可以用前者替换掉后者:
αtminftmini∈[n]∑Wi(t)⋅exp(−yiαtft(x))
现在的策略:因为 αt 只是个标量(可以称为温度),不影响 ft 的训练,所以先固定 αt,优化 ft(但是还是很难)。所以在 AdaBoost 中,我们进行了简化,即用 ft 自己的损失函数和采样权重 Wi(t) 来训练,实际上也大差不差。
固定了 ft 后,接下来要做的就只有优化 αt 了。按照 yi 是否等于 ft(xi) 将数据集分为两部分,上述优化问题等价于
αtminyi=ft(xi)∑Wi(t)exp(−αt)+yi=ft(xi)∑Wi(t)exp(αt)
进行添项减项:
yi=ft(xi)∑Wi(t)exp(−αt)+yi=ft(xi)∑Wi(t)exp(−αt)+yi=ft(xi)∑Wi(t)exp(αt)−yi=ft(xi)∑Wi(t)exp(−αt)
将前面两项合并,发现是 i∈[n]∑Wi(t)exp(−αt),而 ∑Wi(t)=1,所以前两项就剩个 exp(−αt)。
后面两项为 yi=f(xi)∑Wi(t)(exp(αt)−exp(−αt))。标黄的是什么呢?不就是 et 吗!
所以优化问题最终的形式为
αtminexp(−αt)+et(exp(αt)−exp(−αt))
求个导就可以解出 αt 了:
−exp(−αt)+et(exp(αt)+exp(−αt))=0
令 β:=exp(−αt),
−β+(β1+β)etβ=(1−etet)2121loget1−et=0=exp(−αt)=αt
这就是我们为什么要将 αt 这样赋值的原因。
回归问题
现在讨论一下回归问题。我们记得每一步的损失函数为
i∈[n]∑L(yi,gt−1(xi)+αtft(xi))
不过对于回归问题,我们不需要 αt,因为 ft 输出的是个实数,我们可以直接理解为 αt 被吸收进了 ft 中,就没有必要优化两个东西了,只优化 ft 即可。
考虑使用平方损失函数,我们能推出什么样的模型。最优化问题为
ftmin(yi−gt−1(xi)−ft(xi))2
令 ri(t):=yi−gt−1(xi),称为剩余误差(residual error),可以理解为之前的模型没能搞定的“剩余”的误差。所以其实就是,我们迭代地训练新模型 ft 来拟合 {(x1,r1(t)),⋯,(xn,rn(t))}。
此时,若 ft 为树模型,则这样的模型称为 Boosting Tree。
梯度提升模型(Gradient Boosting Model)
(一般而言使用树模型)
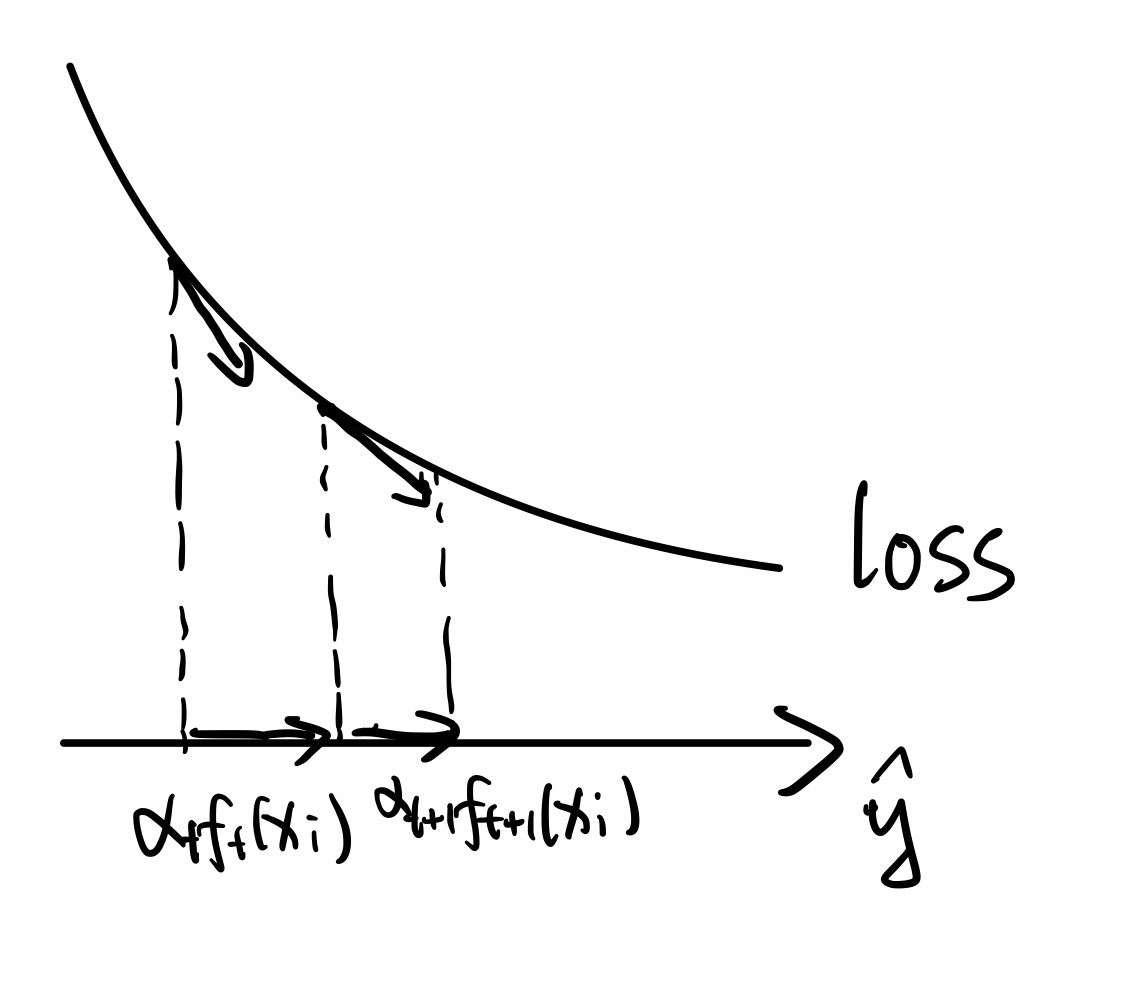
跟之前不同的是,此时不去拟合剩余误差了,而是拟合损失函数的负梯度,即
ri(t):=−∂y^∂L(yi,y^)∣∣∣∣∣y^=gt−1(xi)
即在模型预测值 y^(而非参数)的维度下做梯度下降,如图所示:
例如,对于平方损失函数 L(yi,y^)=21(yi−y^)2,其负梯度 −∂y^∂L(yi,y^)=yi−y^,其实就是之前提到的剩余误差,说明使用平方损失函数的情况下用梯度提升等价于拟合剩余误差。
介绍工业界模型 XGBoost:
进行二阶优化,对树模型复杂度的正则化,以及某些并行技术
很高效的模型。